.png)

Founded by Allan Jiang & Jianyu (Leo) Li
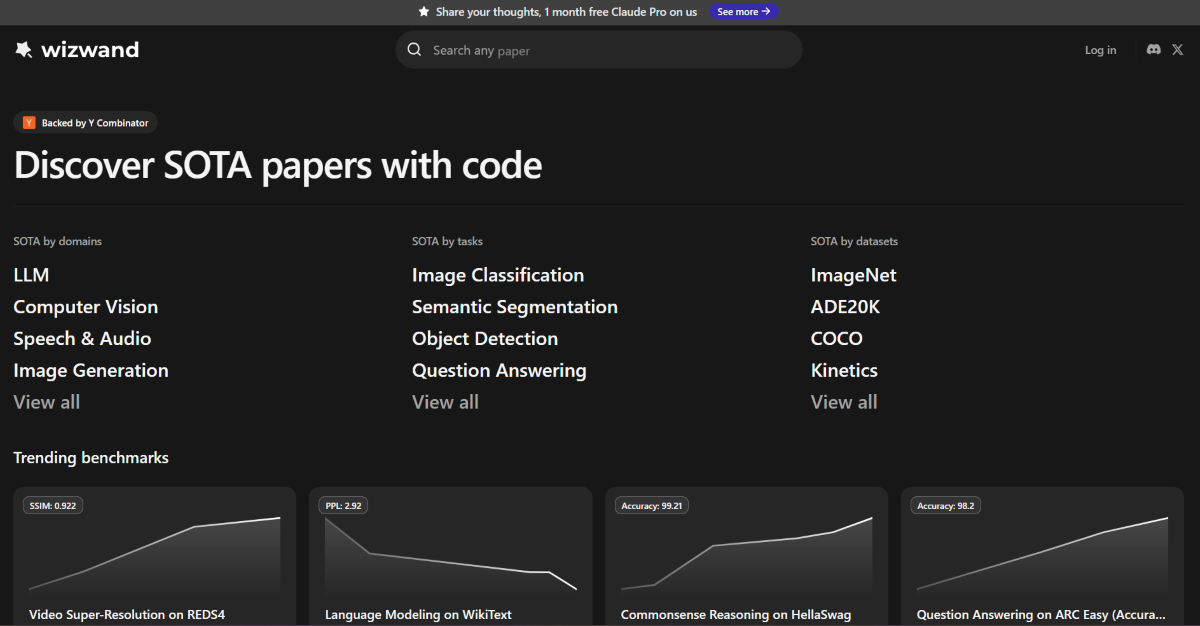
Introducing Wizwand: they help improve reproducibility and transparency in AI/ML research, by allowing research engineers to easily find, implement, and compare the performance of SOTA papers and methods.
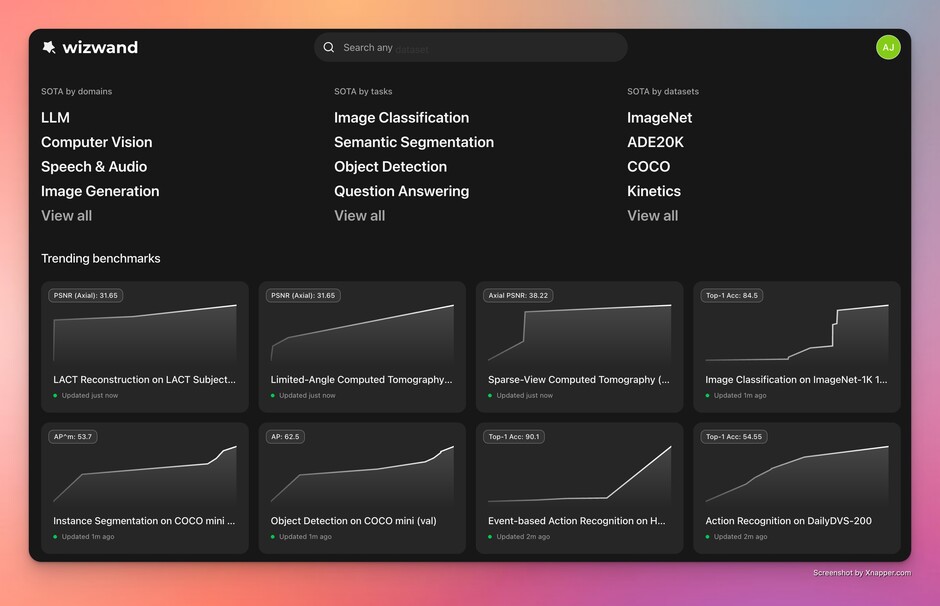
The AI/ML boom hasn’t just increased the number of papers — it has fragmented the landscape. With thousands of preprints hitting arXiv each month, the “state of the art” (SOTA) in a specific niche can change over a weekend. For researchers and research engineers, the cognitive overhead of filtering through incremental gains to find true architectural breakthroughs has become unsustainable. Wizwand is built to help people track AI/ML research progress across a wide range of domains.
Over the past many years, several products have tried to solve this problem, but the Wizwand founders have seen a few common issues:
- Table understanding is hard at scale: Research papers tend to use non-standard tables, which makes extracting the right data points and their correct attributes challenging. A small mistake can produce a wildly incorrect result.
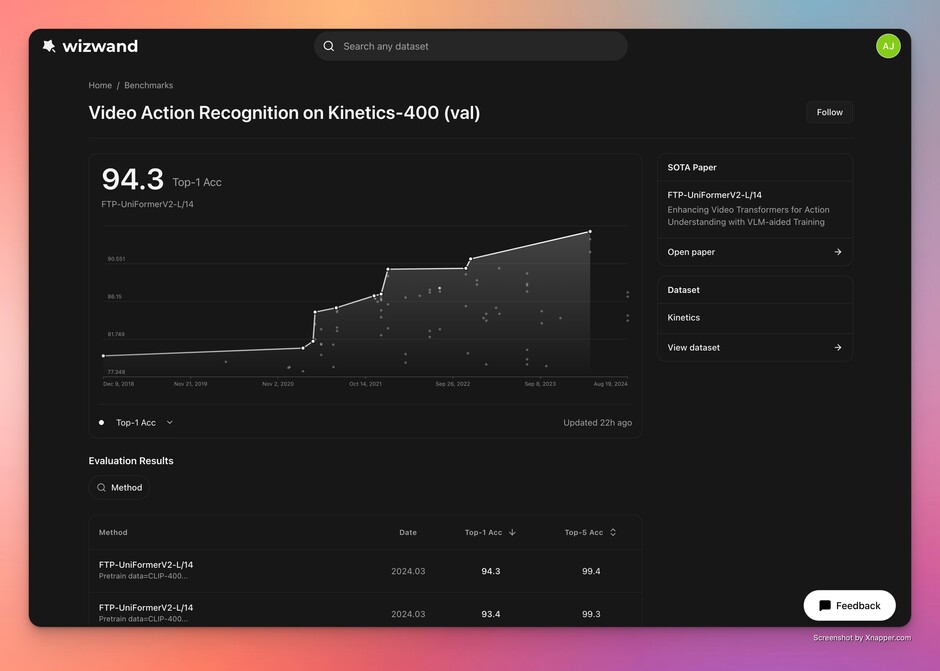
- Apples-to-apples comparison is difficult: Should general image classification methods be compared with medical image classification methods? Should methods tested on the “same” dataset but different versions or splits be compared? When building benchmarks, there hasn’t been a good way to ensure truly apples-to-apples comparisons.
- Table understanding at the paper level is made possible through a combination of LLMs, OCR, and rule-based pipelines. Wizwand can extract data points with complex attributes from tables with high accuracy, including non-standard tables.
- They determine whether two methods are comparable using full-paper understanding — not just dataset and metric. This enables fairer, more meaningful benchmarks.
They’re a team of CS/ML engineers from UC Berkeley, Google, Airbnb, and Microsoft.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Built for Delaware C-Corps. Trusted by 2,000+ startups.
Copyright © Fondo (BloomJoy, Inc.)