"Unsiloed AI builds APIs to parse multimodal unstructured data and convert it into LLM-ready formats. Their vision is to make documents as computable and queryable for AI Agents as your data sitting in an RDS."
TL;DR: Unsiloed AI is building the most accurate APIs for ingesting multimodal unstructured data like PDFs, PPT, DOCX, tables, charts, and images, and converting it into structured Markdown and JSON for downstream LLMs and AI Agents.
They are already processing millions of pages of complex documents each week for Fortune 150 banks, NASDAQ‑listed companies, as well as early‑stage startups in accuracy-sensitive domains like finance, legal, and healthcare.
More than 80% of enterprise data is multimodal and unstructured. AI teams spend 6+ months building accurate document‑ingestion pipelines that keep breaking.
From the tons of open‑source solutions out there, it’s still tough to achieve superior accuracy on even mildly complex cases.
Traditional OCRs are static and break with changing layouts.
LLMs, although good at comprehension, suffer at deterministic extraction, making them unreliable for accuracy‑sensitive domains like finance and healthcare.
Early‑stage vertical AI teams end up becoming document AI companies, reinventing the wheel, as evident from 300+ conversations the founders' have had with AI teams of all sizes.
Solution (What the founders' built)
Unsiloed AI combines vision models with OCR‑based models to accurately extract information from complex documents.
1) Pre‑processing & Segmentation
They segment data into texts, tables, images, and plots using specialized models for each task.
They use a heatmap‑based chunking technique that first generates pivot elements from the document. Pivot elements are the elements of importance, e.g., numbers and merged cells in tables.
This chunking strategy ensures all related pieces of information are preserved in the same chunk (e.g., a table spanning multiple pages, rows split across pages), while unrelated information is split across chunks. The result: retrieval feeds only accurate, complete‑context chunks to LLMs.
2) Dual‑Stream Representation
Post pre‑processing, Unsiloed AI passes the segmented chunks through two parallel streams:
Data Stream: preserves the extracted content.
Layout Stream: preserves the actual layout & hierarchy (indentation, alignment, clause/sub‑clause structure).
This matters because the data is not just text and numbers the structure carries meaning (e.g., a right‑aligned cell in a financial table or the way clauses/sub‑clauses are arranged). The dual stream captures both semantic content and structural cues.
3) Domain‑Specific Decoder
A decoder consumes both the streams and structures the outputs as per the required JSON schema or Markdown.
Unsiloed AI incorporates domain‑specific ontologies (finance, healthcare, legal).
An in-built RL pipeline to train the decoder when outputs involve internal terminology that is hard to capture using a general LLM.
They generate confidence scores for each extracted item; low‑score items are collected over time to run fine‑tuning jobs.
Unsiloed AI can run all of this under fully air-gapped on-premise environments as well for privacy-sensitive verticals.
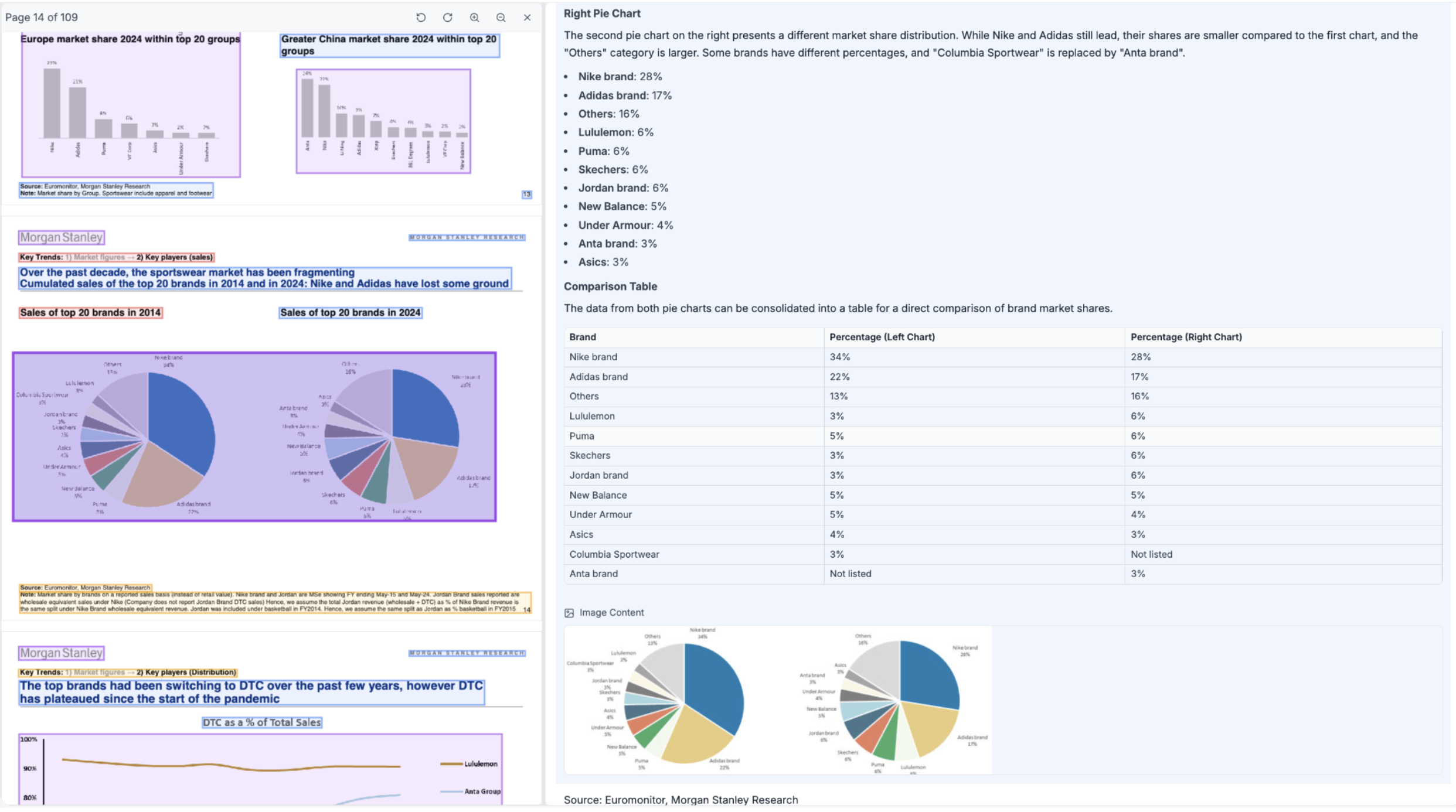
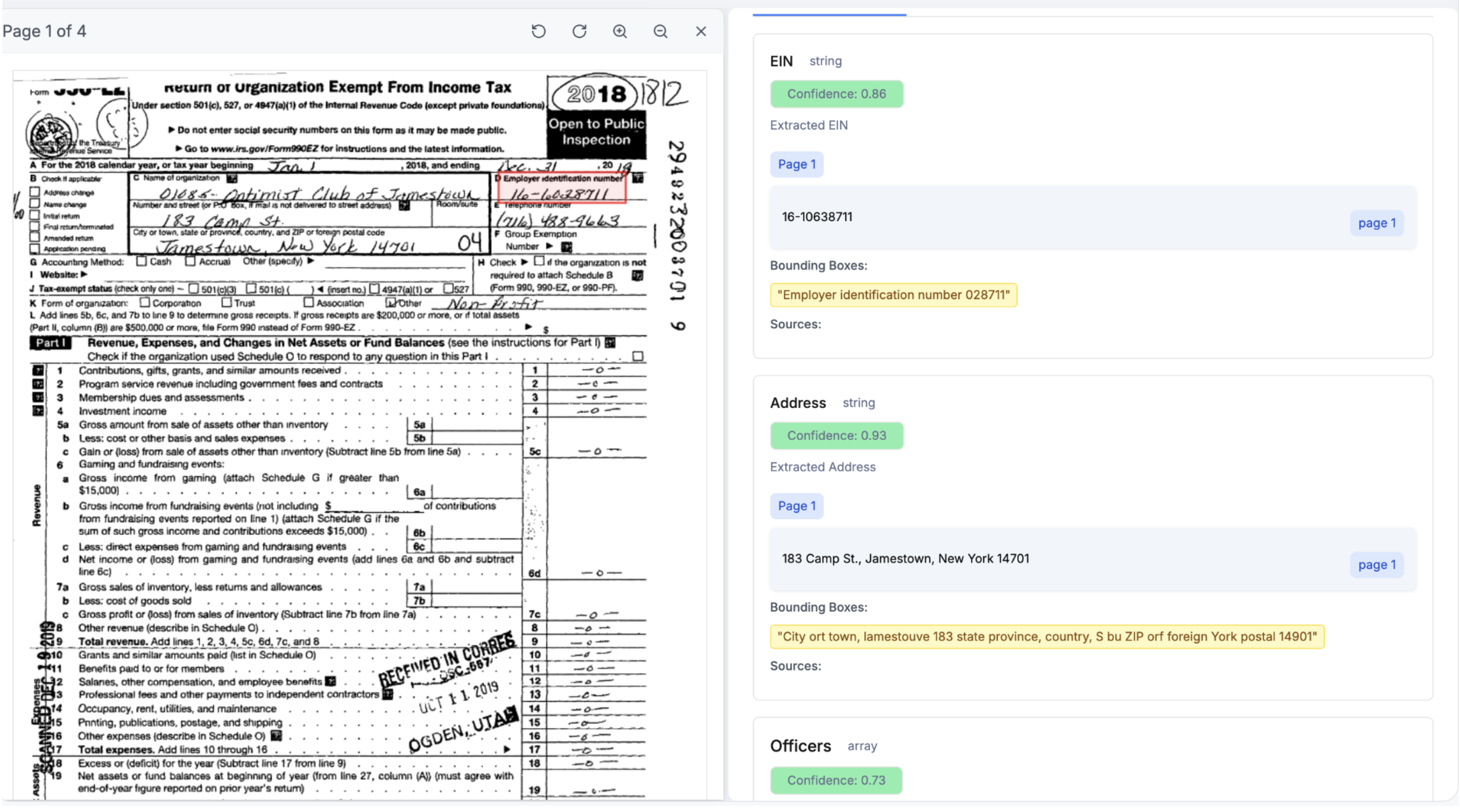
Here are some sample outputs generated by their Vision Models:
PIE Chart formatted markdown
JSON output from handwritten, scanned docs, along with confidence scoring and citations
The Progress
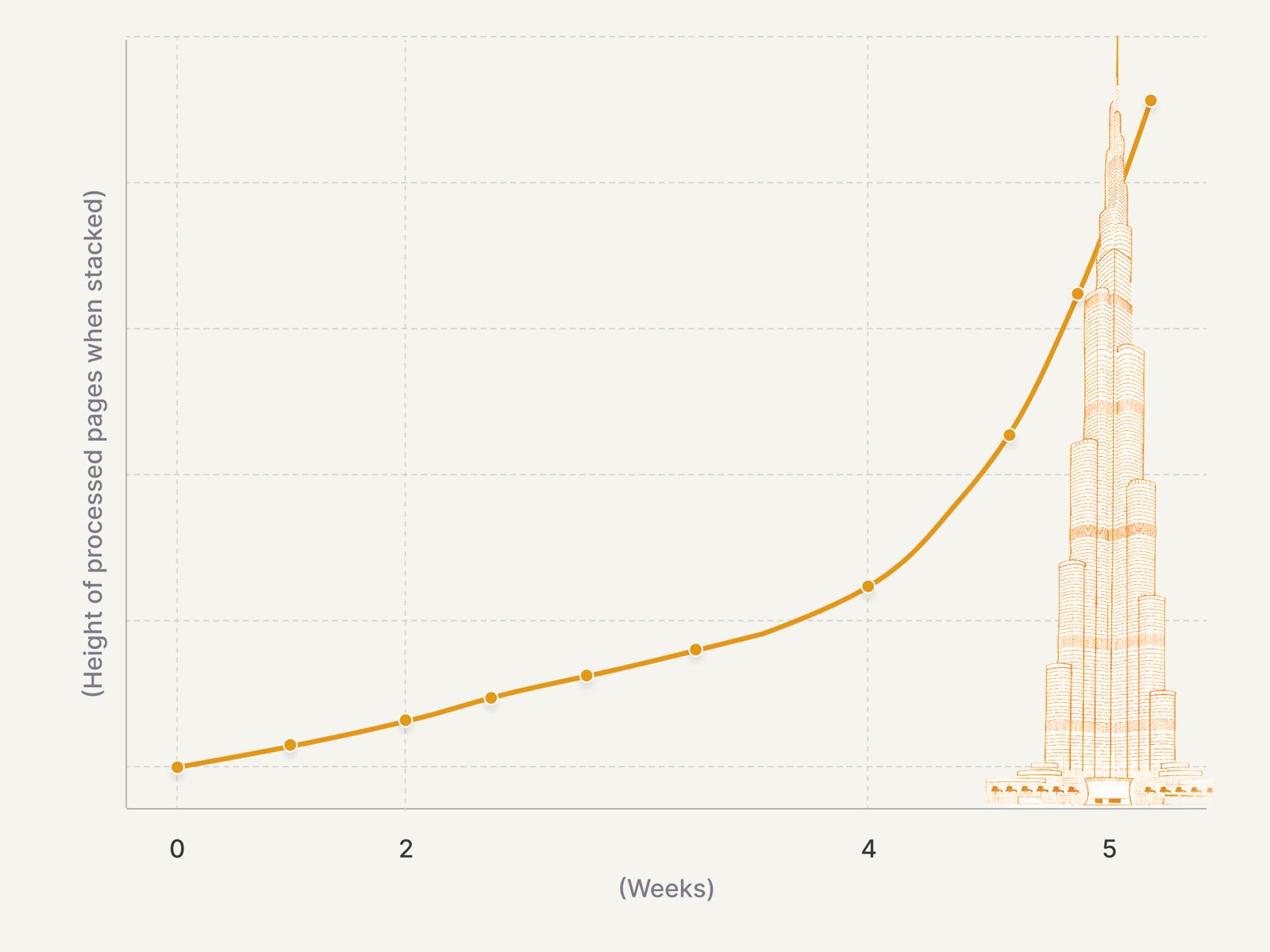
Unsiloed AI has already processing millions of pages for Fortune 150 banks, NASDAQ‑listed companies, as well as early‑stage startups (including 10+ YC startups) across finance, legal, and healthcare. On public benchmarks, they consistently outperform solutions from LlamaIndex, Gemini, Mistral, and Unstructured.io, among others.
Here is a representation of the volume of pages they have processed, stacked on top of each other.
Parsing PDFs, images, PPTs, or Excel files for your Vertical AI use case or RAG pipeline? Give Unsiloed AI a try. They turn months of ingestion work into one API call for every document type.
Sign up on unsiloed.ai to give it a try (no credit card needed).
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
.png)