.png)


Founded by Ben Koska, Luk Koska & Tom Koska
Three brothers that have been working on Artificial Intelligence together for years, most recently training their own Foundational World Models. SF Tensor was born out of their own needs as AI researchers scaling up training runs to thousands of concurrent GPUs.
Ben has been publishing AI research since high school, solo-training models across 4,000 GPUs as co-PI on a 6-figure grant.
Tom and Luk (twins btw) have been doing AI research for years, from starting college in parallel to high school at age 14 to finishing their BSc in CS (at age 16).

Training AI should mean developing smarter architectures and finding better data. But right now, it doesn’t. Teams waste their time on everything but actual research:
This drives up costs, frustrates everyone and kills velocity. Infrastructure has inadvertently turned into the limiting factor for AI research labs, and it’s killing progress.
They experienced this first-hand developing their own foundation models – what they expected to be AI research, experimentation and iterative improvement turned out to be an ugly mix of writing CUDA, debugging driver mismatches and optimizing inter-GPU collective operations. That’s why they decided to solve the infrastructure layer, to allow other researchers to focus on research, not infrastructure.
SF Tensor is the "set it and forget it" infrastructure layer for anyone training or fine-tuning AI models. Hook up your repo, pick your GPU count and budget, and they deal with the rest:
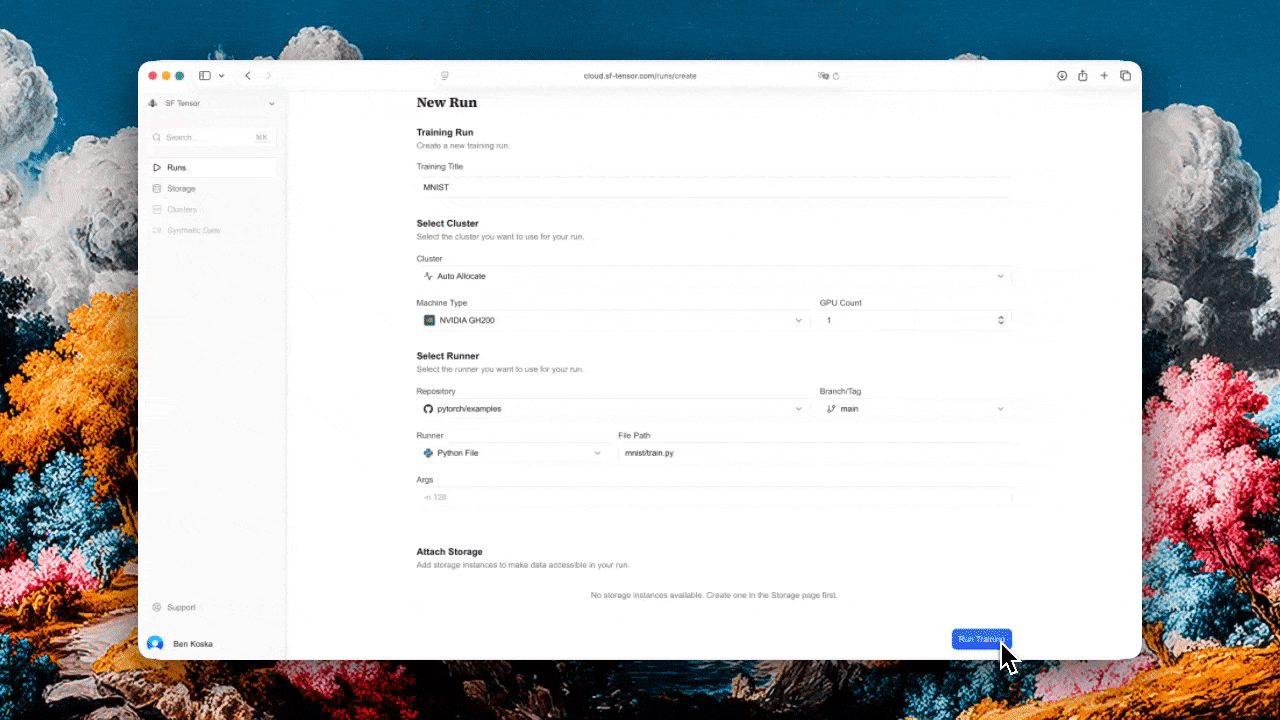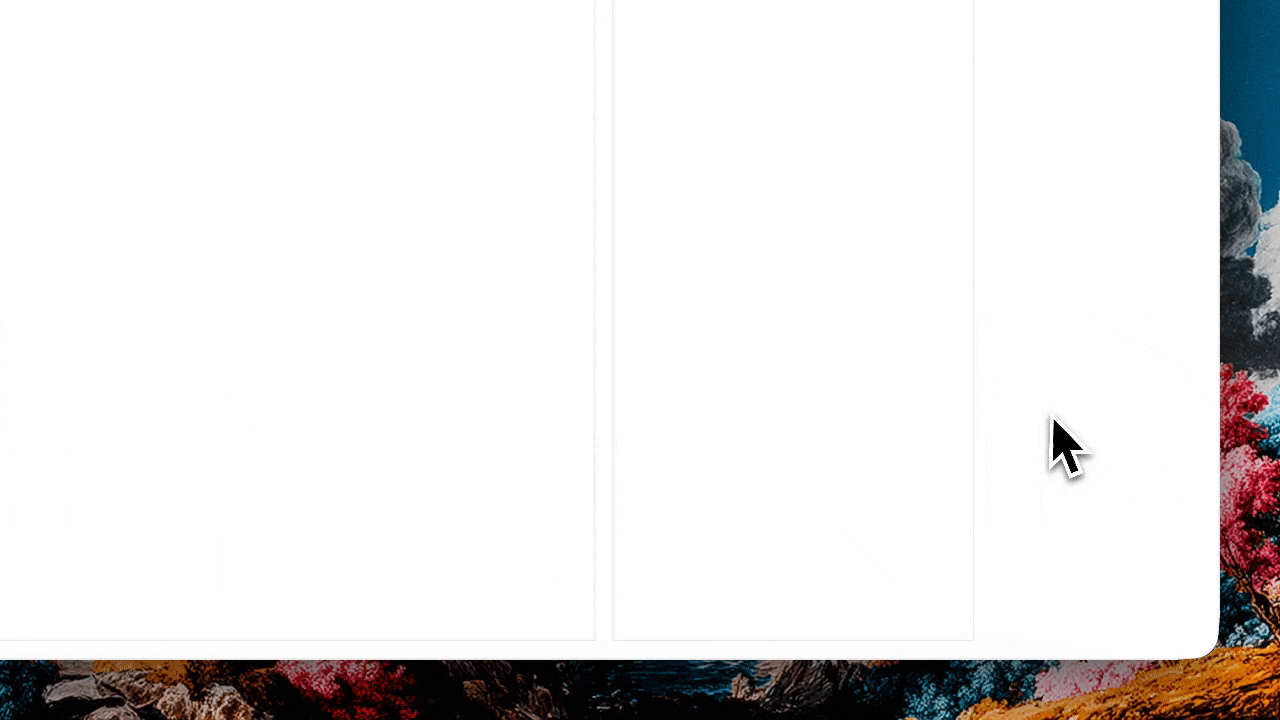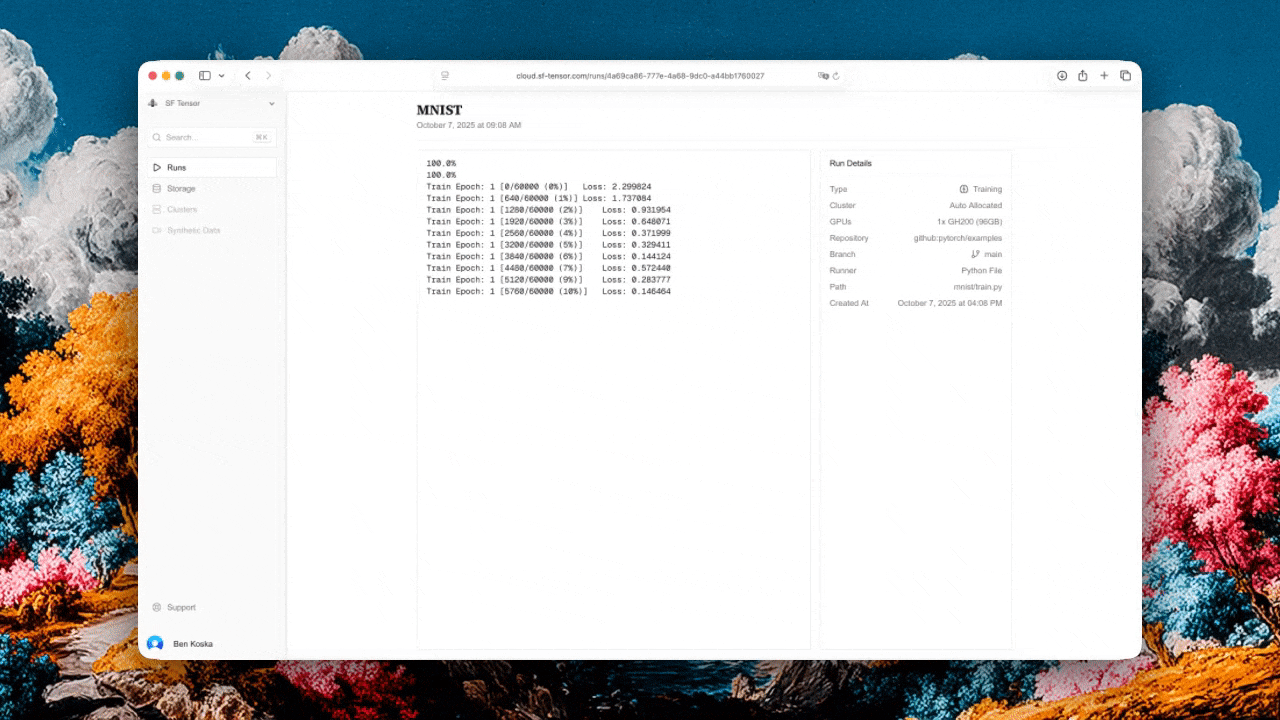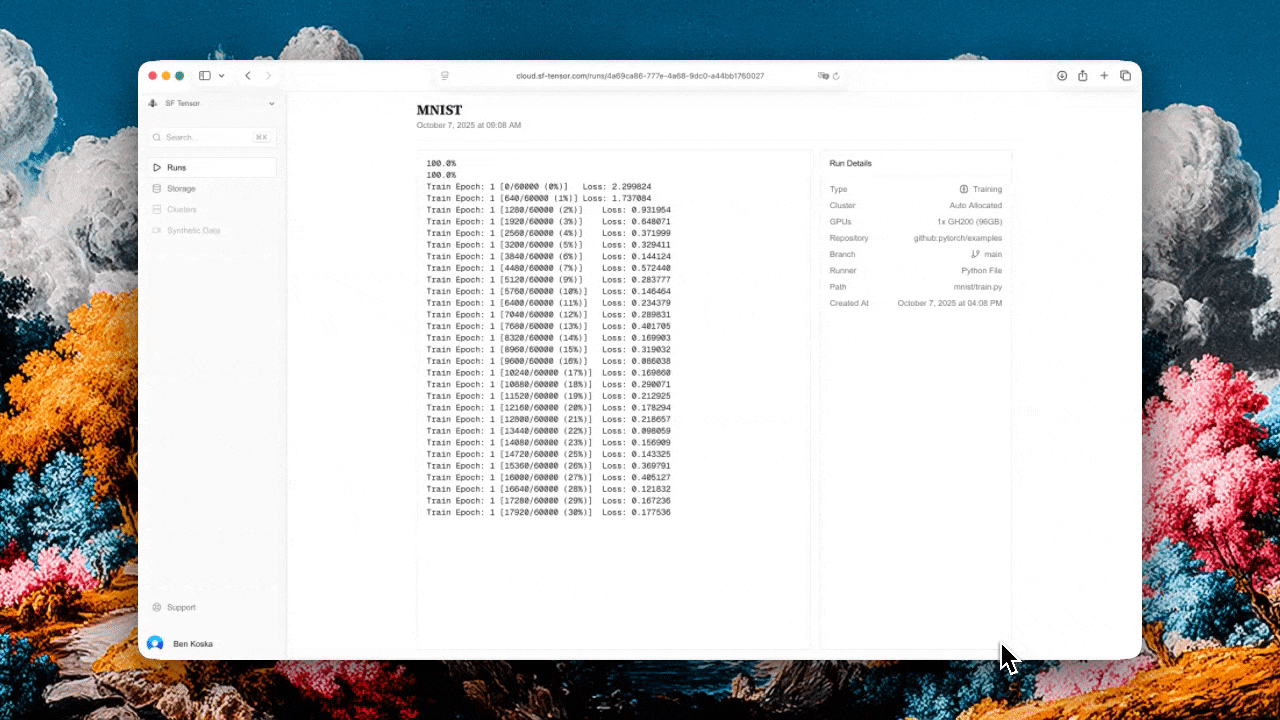
Try them right now at sf-tensor.com or contact them at hello@sf-tensor.com to see how they can help with your infra pains.

Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Built for Delaware C-Corps. Trusted by 1,000+ startups.
Copyright © Fondo (BloomJoy, Inc.)