.png)


Founded by Kenny Dao & Vrushank Gunjur
They just graduated from Stanford (BS + MS, CS) and both spent time in quantitative finance, where data is the answer to every question. They have known each other since the first days of college, and have been close friends and collaborators ever since.
Collectively, they have conducted cutting-edge AI and cryptography research, constructed highly profitable trading strategies, and built core engineering infrastructure for some of the most sophisticated institutions in the world.
They believe that data-rich simulation environments are the next frontier in analytics. Their goal is to build them with the right safeguards and privacy standards from day one. They ultimately want to help organizations build better solutions for humans.
Software cycles are faster than ever, but the feedback loop hasn’t kept up. Teams still learn what worked only after a launch, when fixes are costly and the damage is done. Testing is tedious and fragile, and even with AI involved, it rarely reflects how real users actually behave. Canary deploys and feature flags offer some protection if you have scale, but they still put real users at risk. A/B tests add time and cost, so teams narrow their experimentation and overlook better ideas.
The result: teams are still building for users they don’t truly understand.
Sanctum creates user models that behave like your real customers, built from session recordings and a mix of rich synthetic data and real usage patterns. Their methods are grounded in recent research on audience-aligned user behavior simulation and their own modeling techniques based on alternative data. They then unleash the agents on your new product changes, like an artificial canary deployment.
If your apps are containerized, they can spin up your full stack with forked DBs and dependencies inside ephemeral cloud environments to run simulations with integrated telemetry for bug diagnosis and profiling via our SDK. If you aren’t containerized, they can still run the simulations by attaching to your dev or staging URLs. Results can optionally be fed back to AI tools via MCP.
You get a preview of how real users will react, where they stumble, and what breaks.
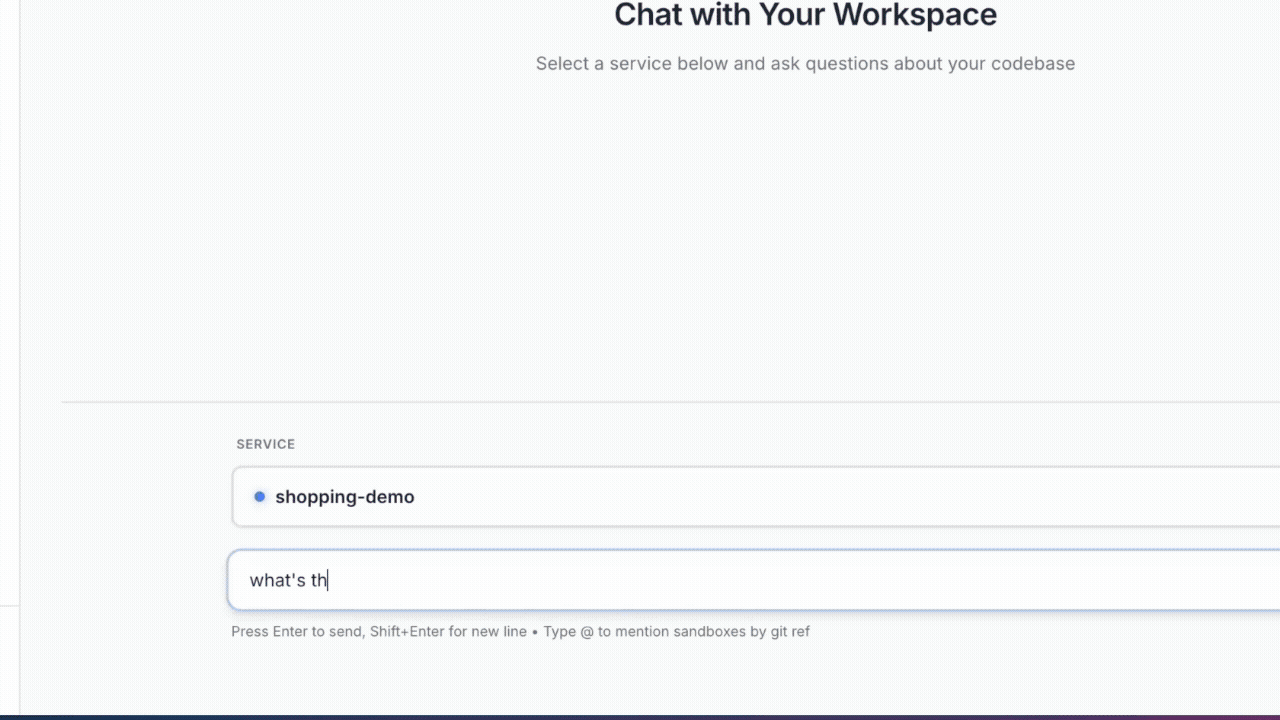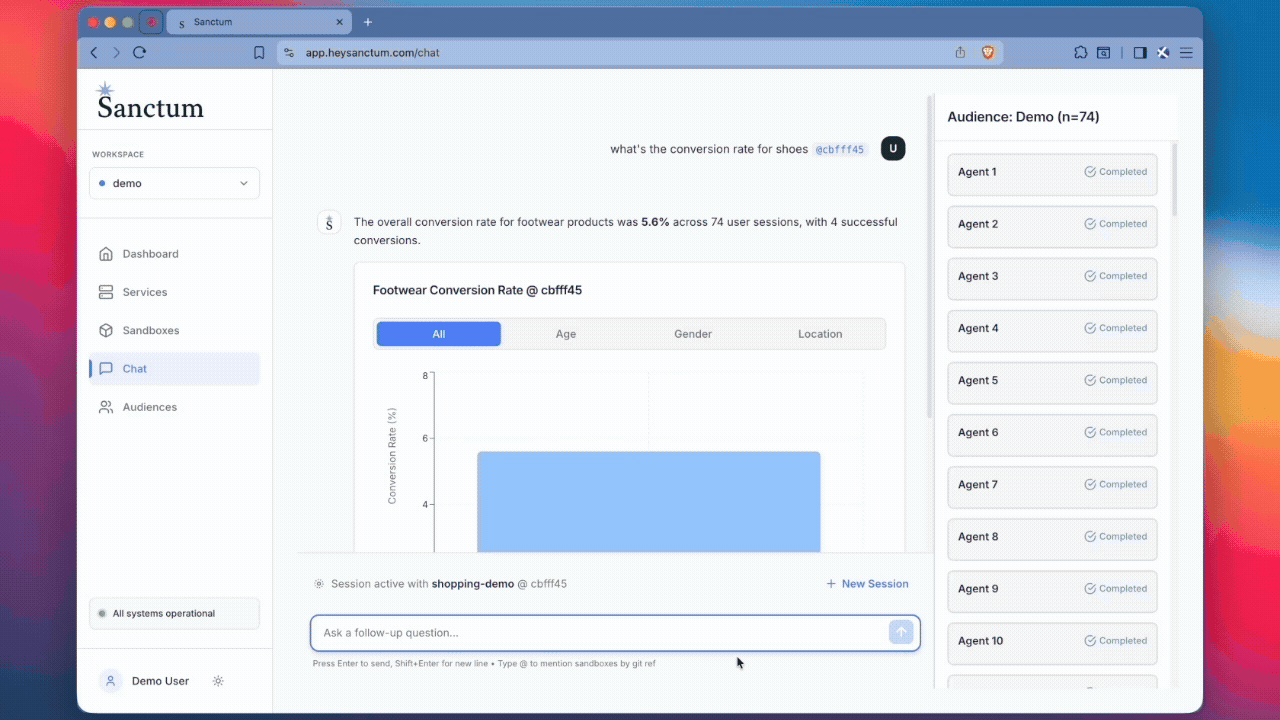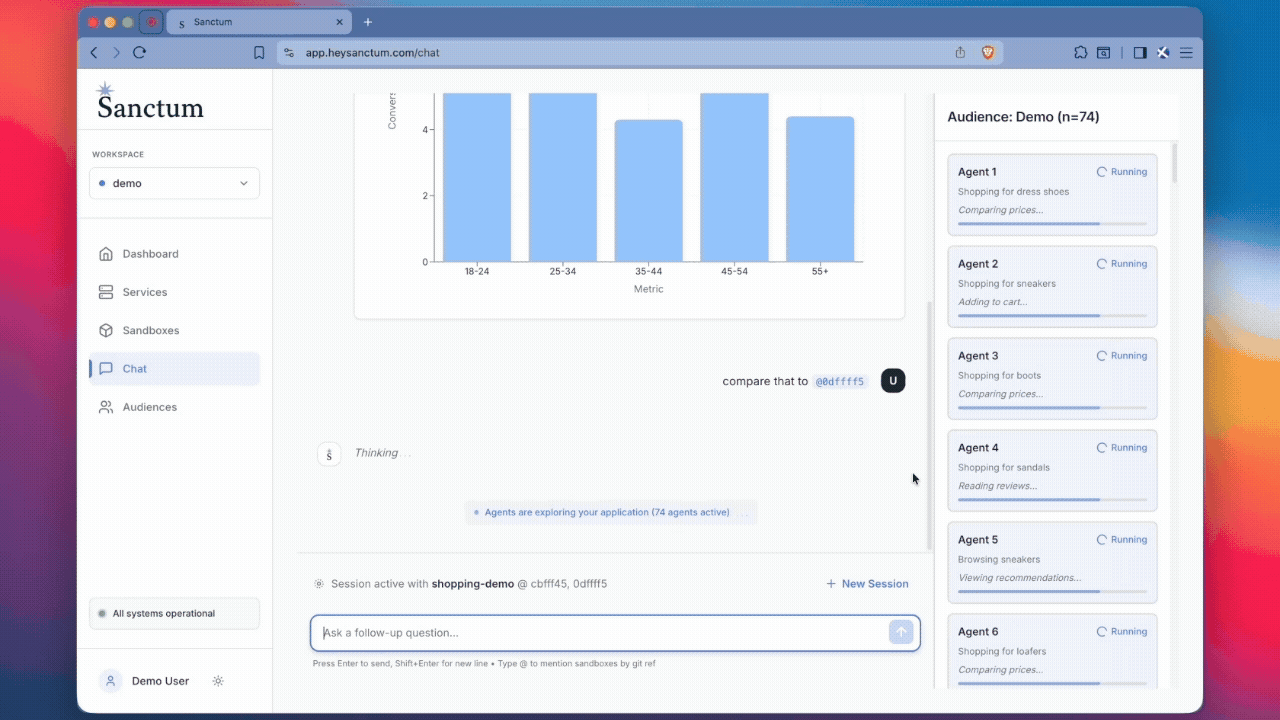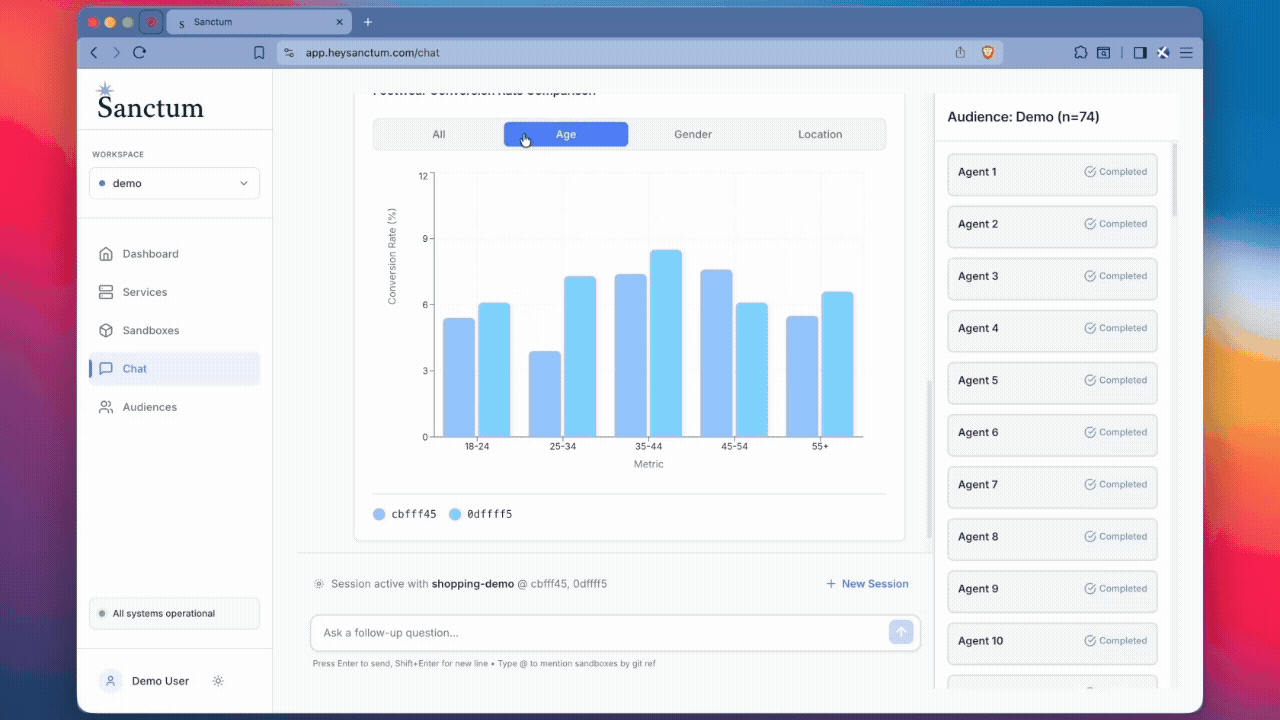
Get artificial users built from real, anonymized user profiles endowed with your session recordings and customer data to interact with your product and answer your questions. They can scale to thousands of parallel simulations at a time and use SSR to provide meaningful metrics.
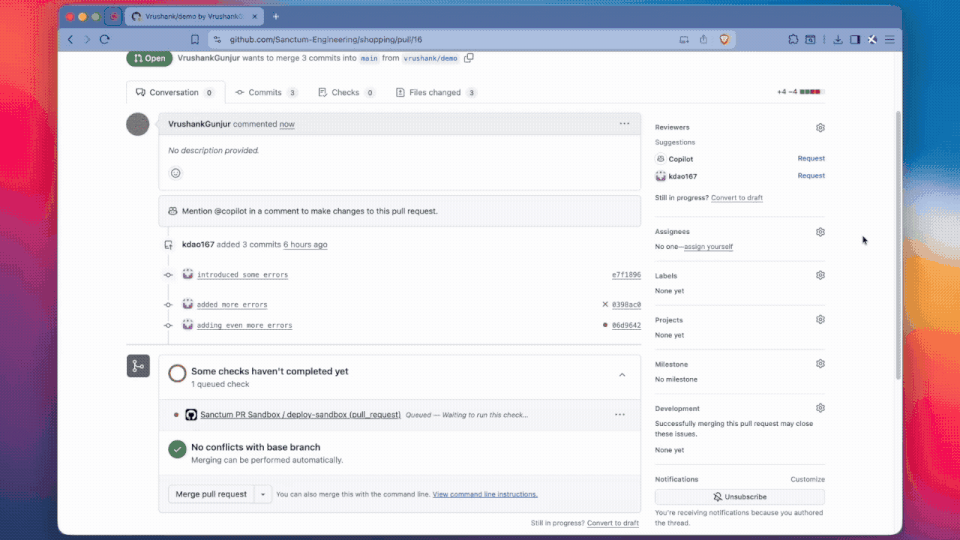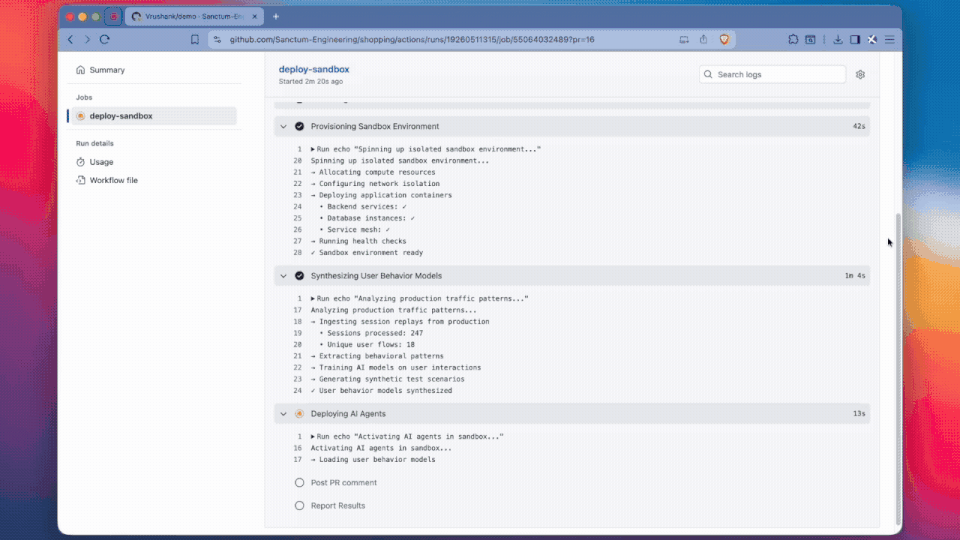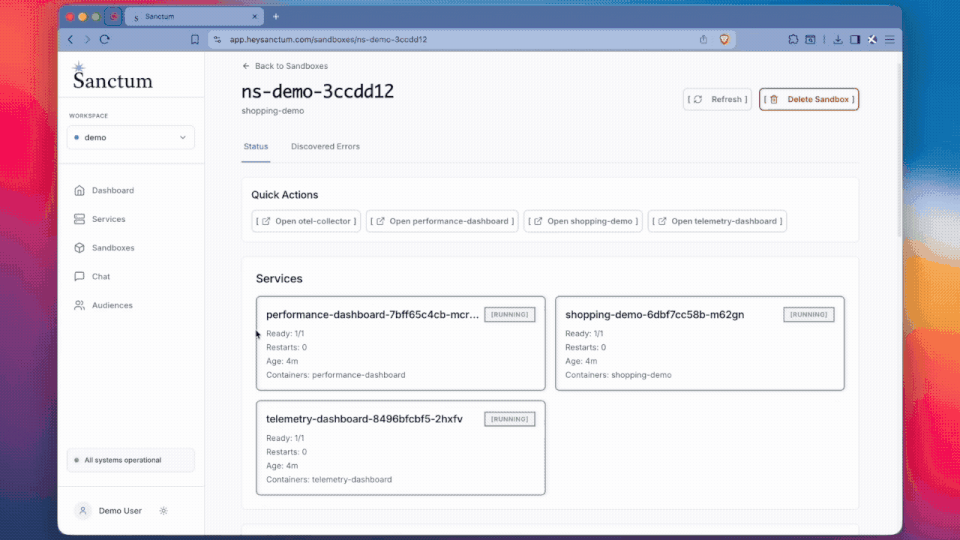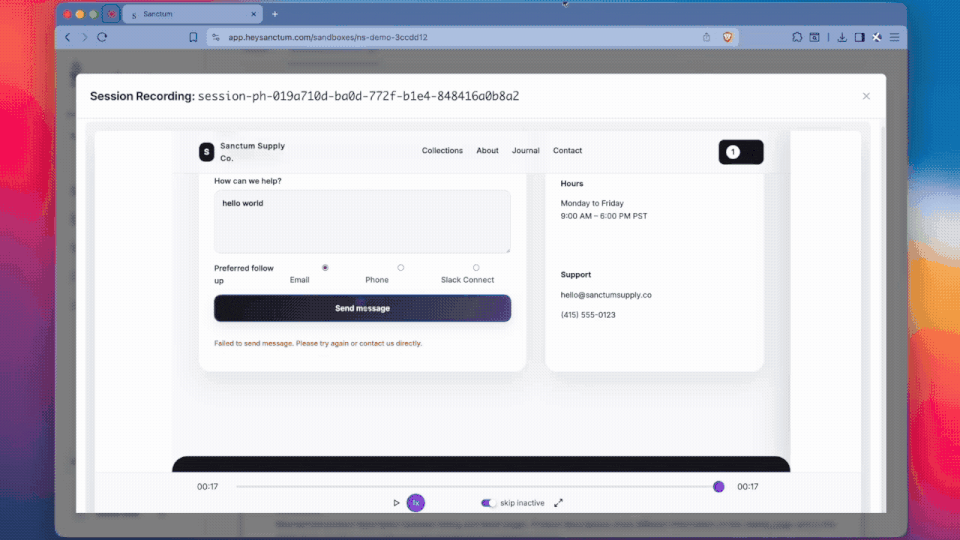
Whenever you make a PR, their GitHub action will trigger a “simulated prod” canary deployment and surface recordings of discovered bugs from smoke tests and diff-inferred test paths. This can also be triggered via CLI. Their SDK which wraps OpenTelemetry can help diagnose these issues.
As agents continue to improve, their interactions with software will become indiscernible from human behavior. Their agents will be able to interact with your application in any form: web, mobile, video, voice, and more.
Building user models based on your target audience gives product and engineering teams a powerful tool to test and learn at scale. While it’s not a replacement for talking to customers, it allows you to explore a larger idea space, identify promising directions earlier, and iterate faster.
As agent traffic grows, they aim to make agent usability and UX feedback a signal for developers. The team is building the devtool for engineers and product teams that closes the loop on feature development: use AI tools to build your software, and use us to evaluate it.
If you:
The team would love to hear from you! Email the founders here or book a call / express interest at heysanctum.com

Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Built for Delaware C-Corps. Trusted by 1,000+ startups.
Copyright © Fondo (BloomJoy, Inc.)


.png)

