.png)


Founded by Preston Zhou & Eitan Borgnia
Hey everyone 👋 Meet Preston and Eitan, the cofounders of Relace.
Agentic coding systems are easy to prototype, but hard to make robust. As users succeed at creating more complex designs/applications, you hit bottlenecks:
Frontier models (like Claude 3.7, o3, etc.) are powerful, but overkill for these auxiliary functions like retrieval and merging. Costs start to add up, especially when every agent action hits an API with thousands of tokens in and out. Plus, non-technical users are easily frustrated by high latency, especially if they are trying to refine small aspects of the code they created.
Relace models are trained to achieve order-of-magnitude improvements in both latency and cost without compromising on accuracy.
Instant Apply:
Released in February, this model merges semantic code snippets at 2,500 tokens/sec with an average end-to-end latency of ~900ms across Relace users.
Inspired by Cursor's Fast Apply, the semantic diff format is chosen to be natural for all models to output. A simple prompt change combined with Instant Apply can reduce Claude 3.5/3.7 token usage by ~40%.
Relace trains on hundreds of thousands of code merges across dozens of different coding languages to achieve SOTA accuracy:

Embeddings and Reranker:
The embedding model + reranker can determine the relevance score for a user request against million-line codebases in ~1-2s. By training on hundreds of thousands of query/code pairs, Relace can effectively filter out irrelevant files and cut input token usage by over 50%.
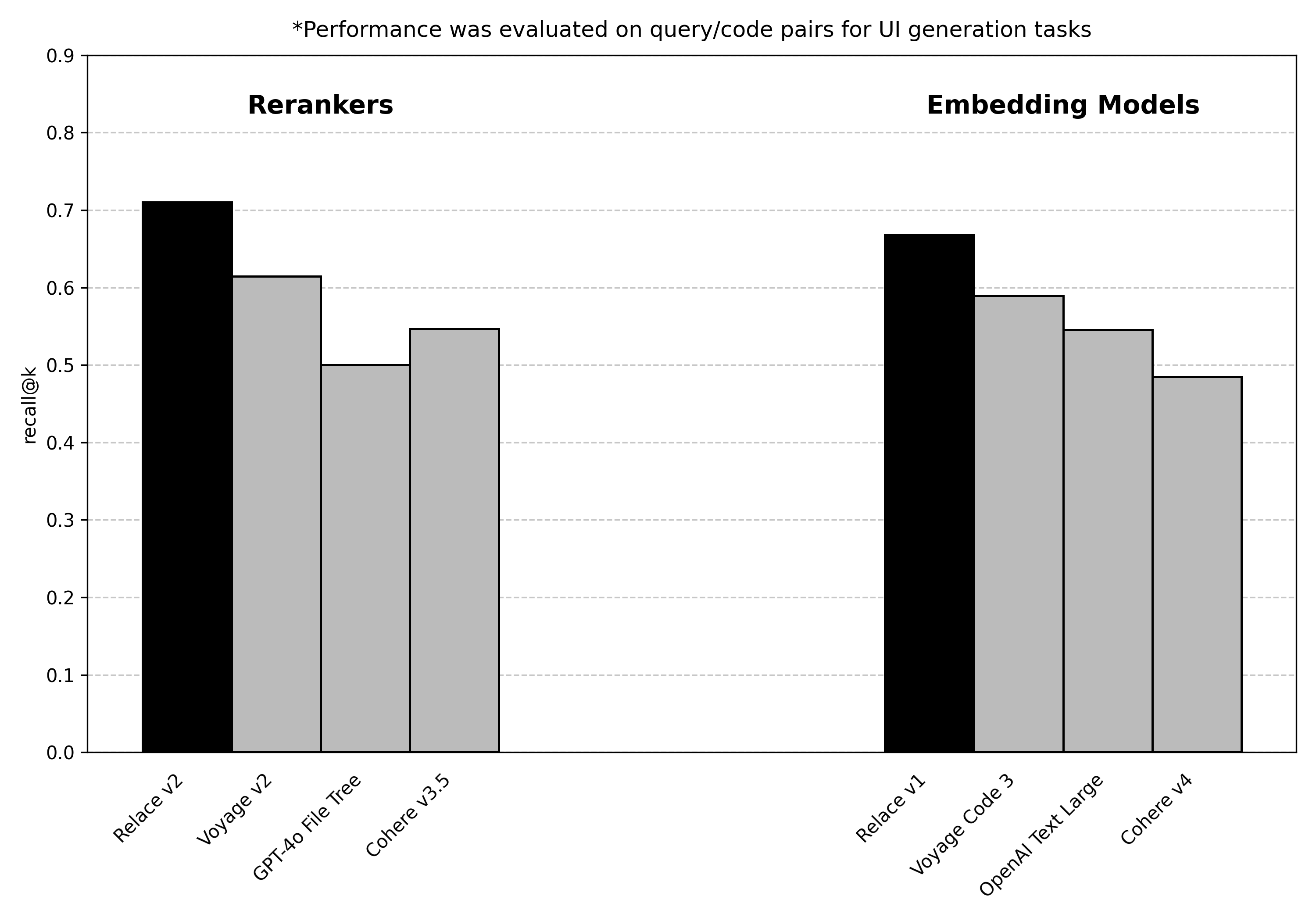
Not only does this save on cost, but cleaning up the context window significantly improves generation quality of the AI agent.
Both of these models are battle tested and running millions of times a week in production. You can read more and try it out for yourself with the links below.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Built for Delaware C-Corps. Trusted by 1,000+ startups.
Copyright © Fondo (BloomJoy, Inc.)




