Jackson (CTO, on the left) optimized the Gemini model at Google for efficient deployment at massive scale. Liam (CEO, on the right) built zero-to-one systems as a software engineer.
The Problem
Fine-tuning frontier models like GPT-4 on proprietary data is expensive, and locks customers into one external closed source model provider.
These large models are 100x the price per-token of smaller Llama 3.1 models, and run nearly 10x slower. This makes them impractical to deploy at scale.
Closed source model lock-in means customers can’t tweak or tune their own model, or deploy on-prem for sensitive data solutions.
The Solution
Model Distillation:
In model distillation, a large teacher model effectively fine tunes a smaller student model without the need for labeled or structured datasets. This ‘condenses’ large models down to the compute cost of small models.
Distillation results in near-frontier model quality, with efficient performance. This means we can achieve 5x the speed at 1/10th the cost.
With the release of Llama 405b in late July, open source frontier distillation became available to the public for the first time.
Growth & Market
Llama model downloads have grown 10x in the last year and are approaching 350 million downloads to date. There were 20 million downloads in the last month alone, making Llama the leading open source model family.
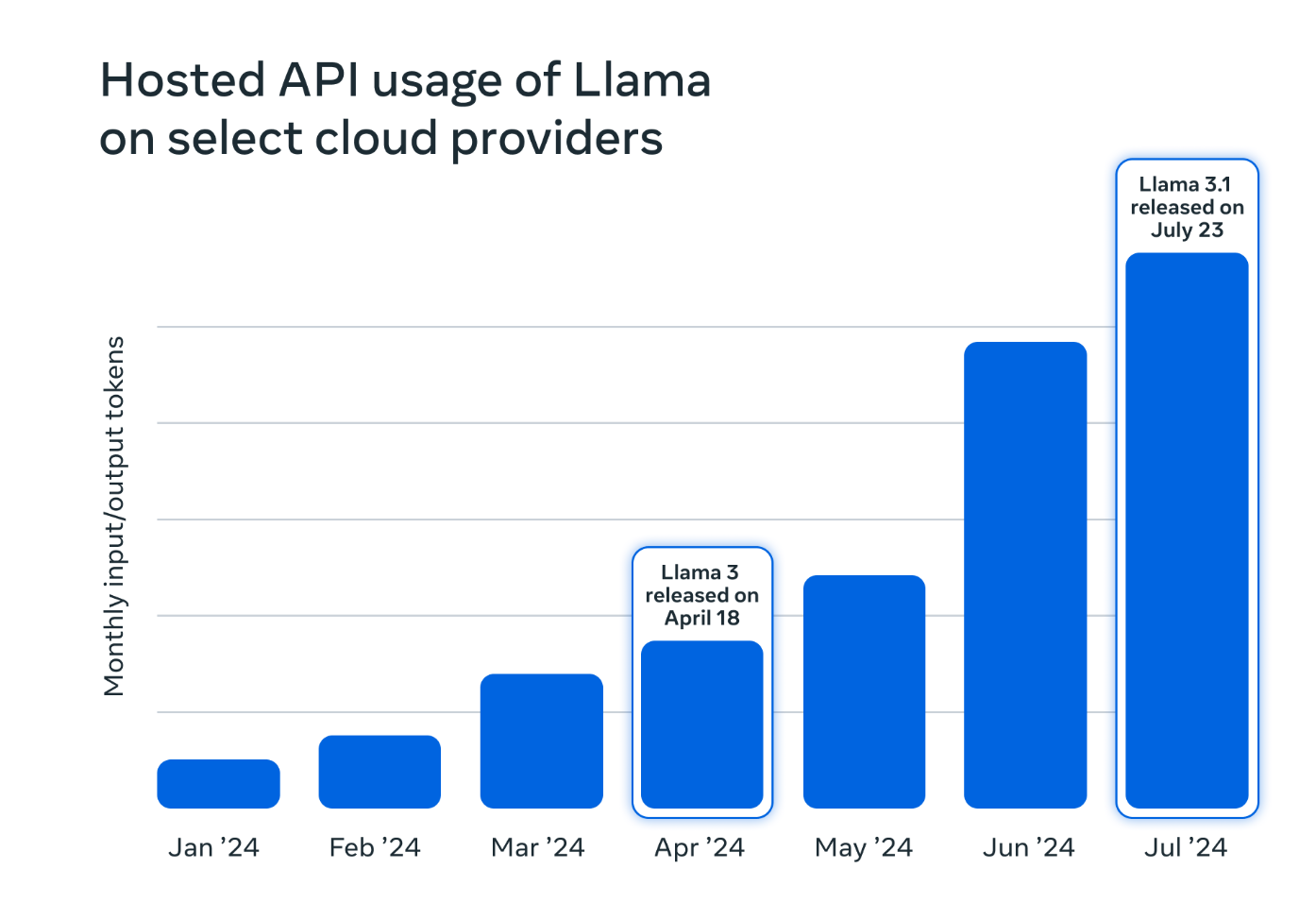
Llama usage by token volume across major cloud service providers has more than doubled in just three months from May through July 2024 when Llama 3.1 was released.
Monthly usage (token volume) of Llama grew 10x from January to July 2024 for some of the largest cloud service providers.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
.png)