.png)

Pipeshift AI recently launched!

Founded by Arko C, Enrique Ferrao & Pranav Reddy
The open-source AI stack is missing, forcing most teams to experiment by duct-taping things like TGI/vLLM but having nothing ready for production. As you scale, it requires expensive ML talent, long build cycles, and constant optimizations.
The gap between open-source and closed-source models is shrinking (Meta's Llama 3.1 405B is a testament to that)! And open-source LLMs offer multiple benefits over their closed-source counterparts:
🔏 Model ownership and IP control
🎯 Verticalization and customizability
🏎️ Improved inference speeds and latency
💰 Reduction of API costs at scale
Pipeshift is the cloud platform for fine-tuning and inferencing open-source LLMs, helping developers get to production with their LLMs faster than ever.
🎯 Fine-tune Specialized LLMs
Run multiple LoRA-based fine-tuning jobs to build specialized LLMs.
⚡️ Serverless APIs of Base and Fine-tuned LLMs
Run inference for your fine-tuned LLMs and pay as per your token usage.
🏎️ Dedicated Instances for High Speed and Low Latency
Use Pipeshift AI's optimized inference stack to get max throughputs and utilization on GPUs.
Product Demo: https://youtu.be/z8z5ILyXxCI
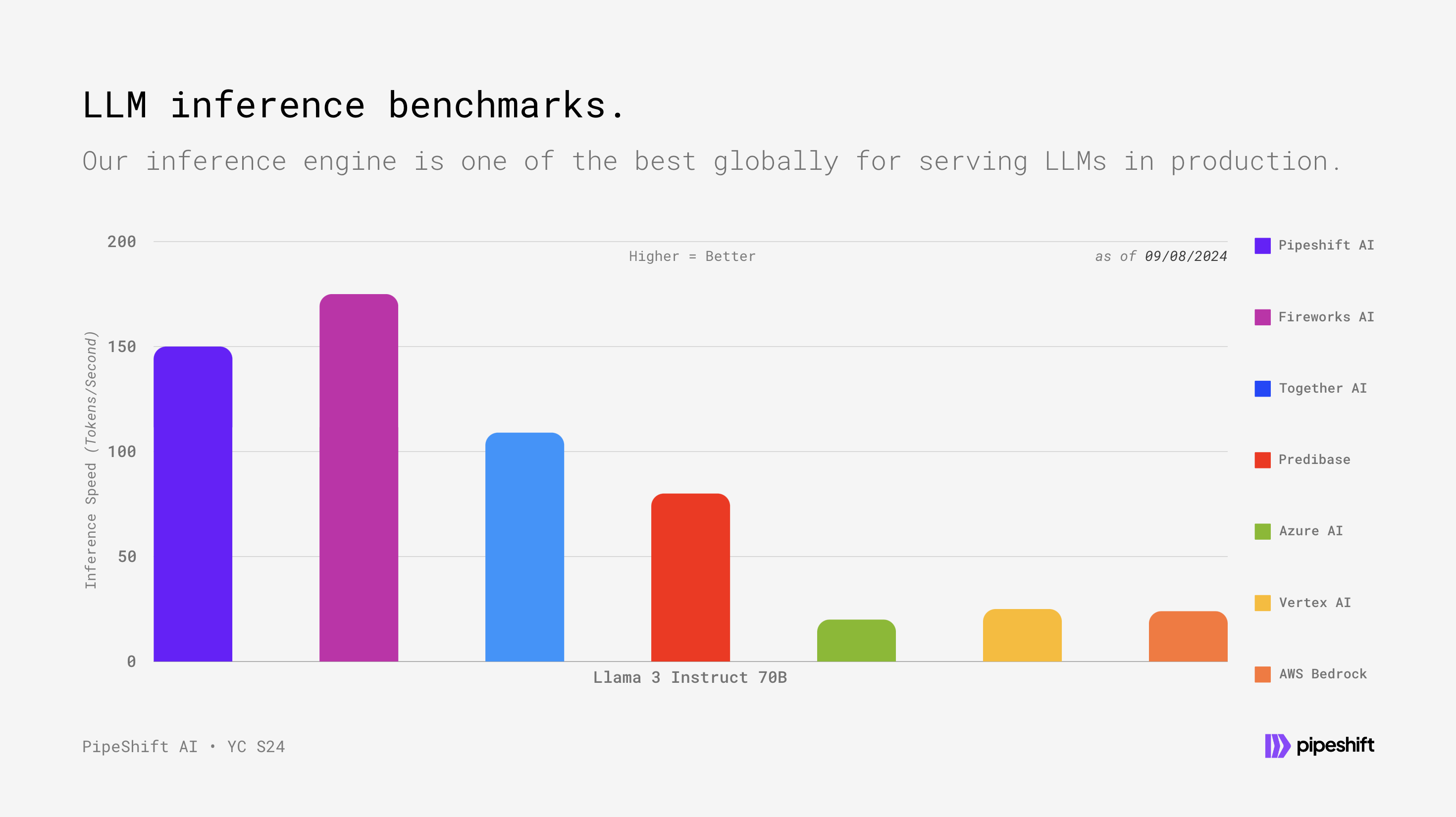
Pipeshift AI's inference stack is one of the best globally, hitting 150+ tokens/sec on 70B parameter LLMs without any model quantization. And, since their private beta access was opened (<2 weeks back), they have already seen 25+ LLMs being fine-tuned with over 1.8B tokens in training data across 15+ companies.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Built for Delaware C-Corps. Trusted by 1,000+ startups.
Copyright © Fondo (BloomJoy, Inc.)




