.png)

Founded by Philippe Noël

ParadeDB recently completed one of their biggest engineering bets to date: migrating pg_search, a Postgres extension for full text search and analytics, to Postgres' block storage system. In doing so, pg_search is the first-ever extension1 to port an external file format to Postgres block storage.
For context - block storage is Postgres’ storage API that backs all of Postgres’ tables and built-in index types. Prior to this migration, pg_search operated outside of block storage. This means that the extension created files which were not managed by Postgres and could read the contents of those files directly from disk. While it’s not uncommon2 for Postgres extensions to do this, block storage has enabled pg_search to simultaneously achieve:
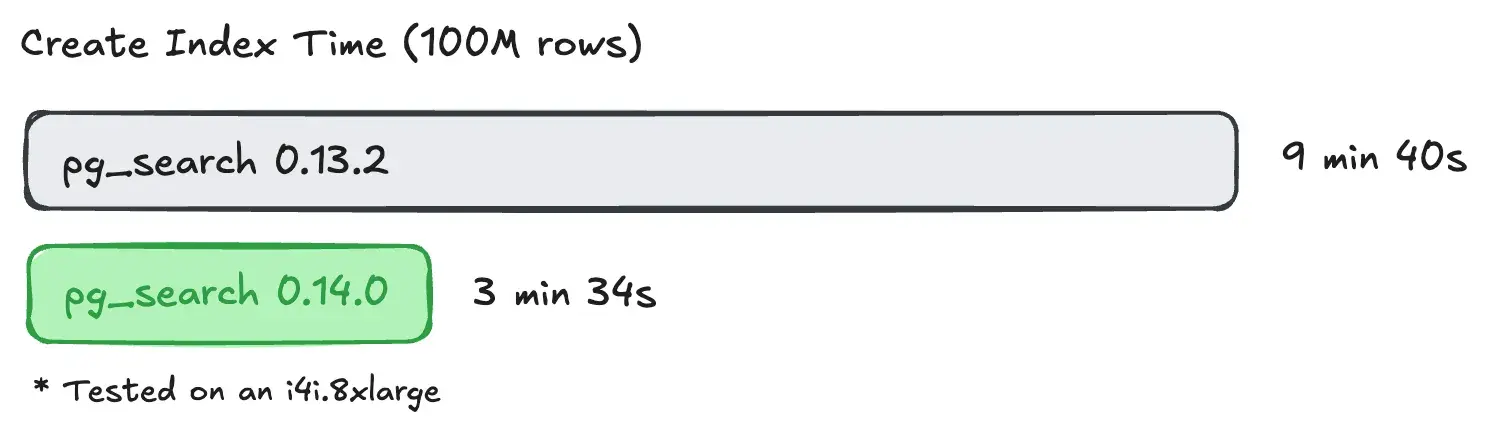
At first, they weren’t sure if reconciling the data access patterns and concurrency model of Postgres and Tantivy — pg_search's underlying search library — was possible without drastic changes to Tantivy3. In this blog post, we’ll briefly dive into how they architected pg_search's new block storage layout and data access patterns.
In the near future, ParadeDB will release two more posts: one to discuss how they designed and tested pg_search to be MVCC-safe in update-heavy scenarios, and another to dive into how they customized the block storage layout for analytical workloads (e.g. faceted search, aggregates).
The fundamental unit of block storage is a block: a chunk of 8192 bytes. When executing a query, Postgres reads blocks into buffers, which are stored in Postgres’ buffer cache.
DML (INSERT, UPDATE, DELETE, COPY) statements do not modify the physical block. Instead, their changes are written to the underlying buffers, which are later flushed to disk when evicted from the buffer cache or during a checkpoint.
If Postgres crashes, modifications to buffers that have not been flushed can become lost. To guard against this, any changes to the index must be written to the write-ahead log (WAL). During crash recovery, Postgres replays the WAL to restore the database to its most recent state.
pg_search is a Postgres extension that implements a custom index for full text search and analytics. The extension is powered by Tantivy, a search library written in Rust and inspired by Lucene.
A custom Postgres index has two choices for persistence: use Postgres block storage or the filesystem. At first, using the filesystem may seem like the easier option. Integrating with block storage requires solving a series of problems:
Once the index overcomes these hurdles, however, Postgres block storage does an incredible amount of heavy lifting. After a year of working with the filesystem, it became clear that block storage was the way forward.
The complete blog post by ParadeDB can be read here. In the following parts of the blog post series, they will dive into more exciting challenges faced with block storage, with a focus on concurrency and analytical performance.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Built for Delaware C-Corps. Trusted by 1,000+ startups.
Copyright © Fondo (BloomJoy, Inc.)




.png)