.png)


Founded by Abhinav Sinha, Andy Liang & Jeremy Tian
Abhinav, Andy, and Jeremy met while playing Super Smash Bros freshman year at Stanford. Since then, they’ve worked on multiple deep learning research projects together. Abhinav (CEO) has worked as a researcher at the Stanford AI Lab, a quant at Citadel and SIG, and a software engineer at Apple. Andy (CTO) qualified to represent Stanford (one of three) at the North American Championship for the largest collegiate programming competition in the world (ICPC). Jeremy (Chief Scientist) is a dedicated machine learning researcher with years of experience working on state-of-the-art models at Steel Dynamics (F500) and DRW.
When the founders started building agents, it seemed trivial: Call GPT a few times, string together some logic, and it works—until it doesn’t.
The moment you become complex, it’s a disaster. One day, your agent is working fine; the next, it’s breaking for no reason. With misaligned reasoning, brittle logic chains, unclear failure cases, or silent performance degradation, you end up spending hours rerunning prompts, tweaking edge cases, and wondering why something that should work just doesn’t.
And don’t even get them started on debugging. Running the same prompt over and over again, hoping this time it’ll behave the way you want? That’s not a strategy—it’s a nightmare.
Lucidic changes the game. No more late nights staring at a terminal, guessing what went wrong. See exactly how your agent’s brain works—replay actions step by step, inspect decision trees, and visualize internal reasoning in real time. Modify prompts and logic with instant, structured feedback so you’re never debugging in the dark again.
No more trial-and-error fixes—just clear, interactive breakdowns of why your agent fails and how to fix it. Test at scale, compare behaviors side by side and optimize performance before deployment. Intelligently visualize thousands of complete workflow trajectories at once, showing success rates, failure points, and decision paths for faster debugging.
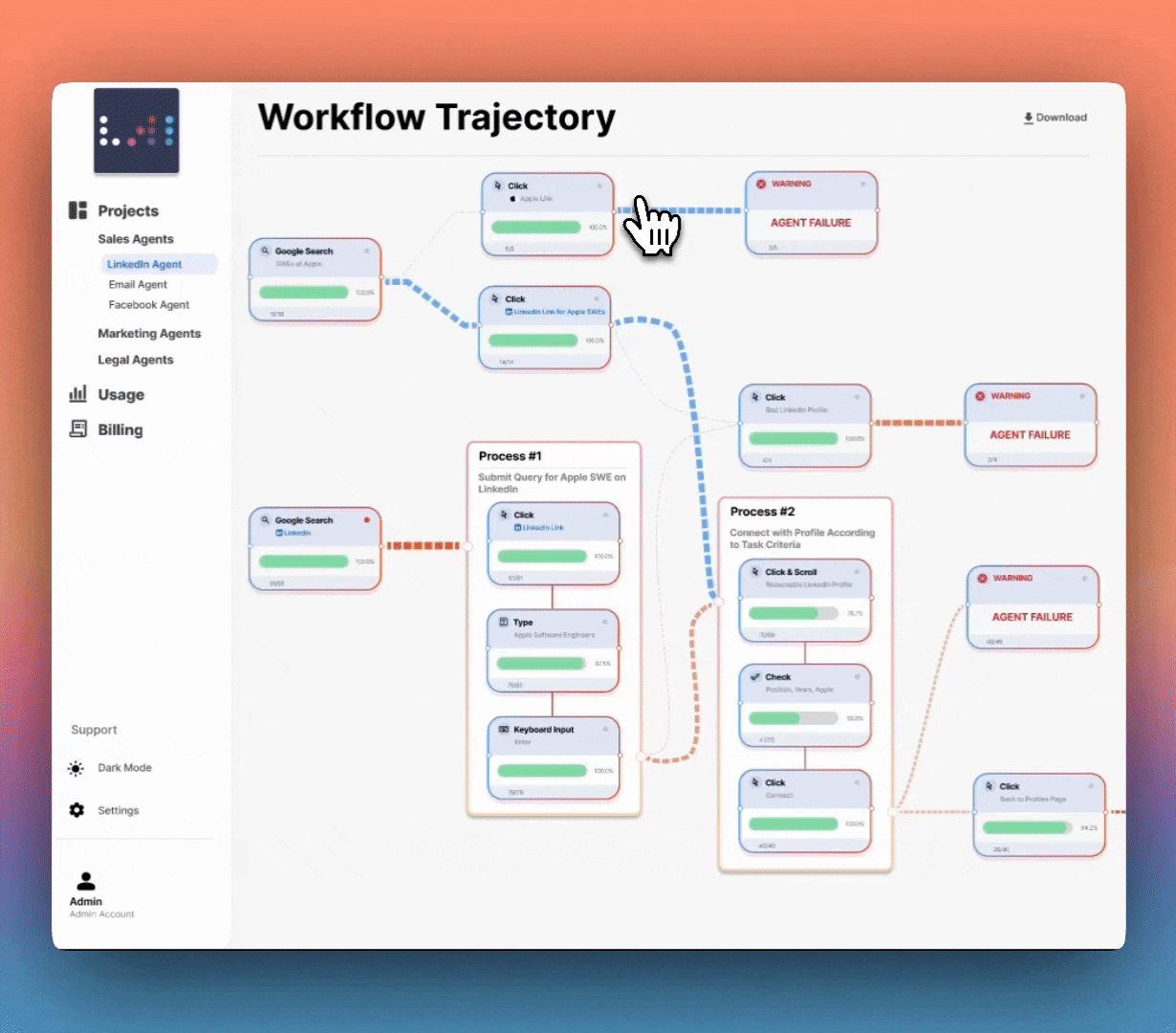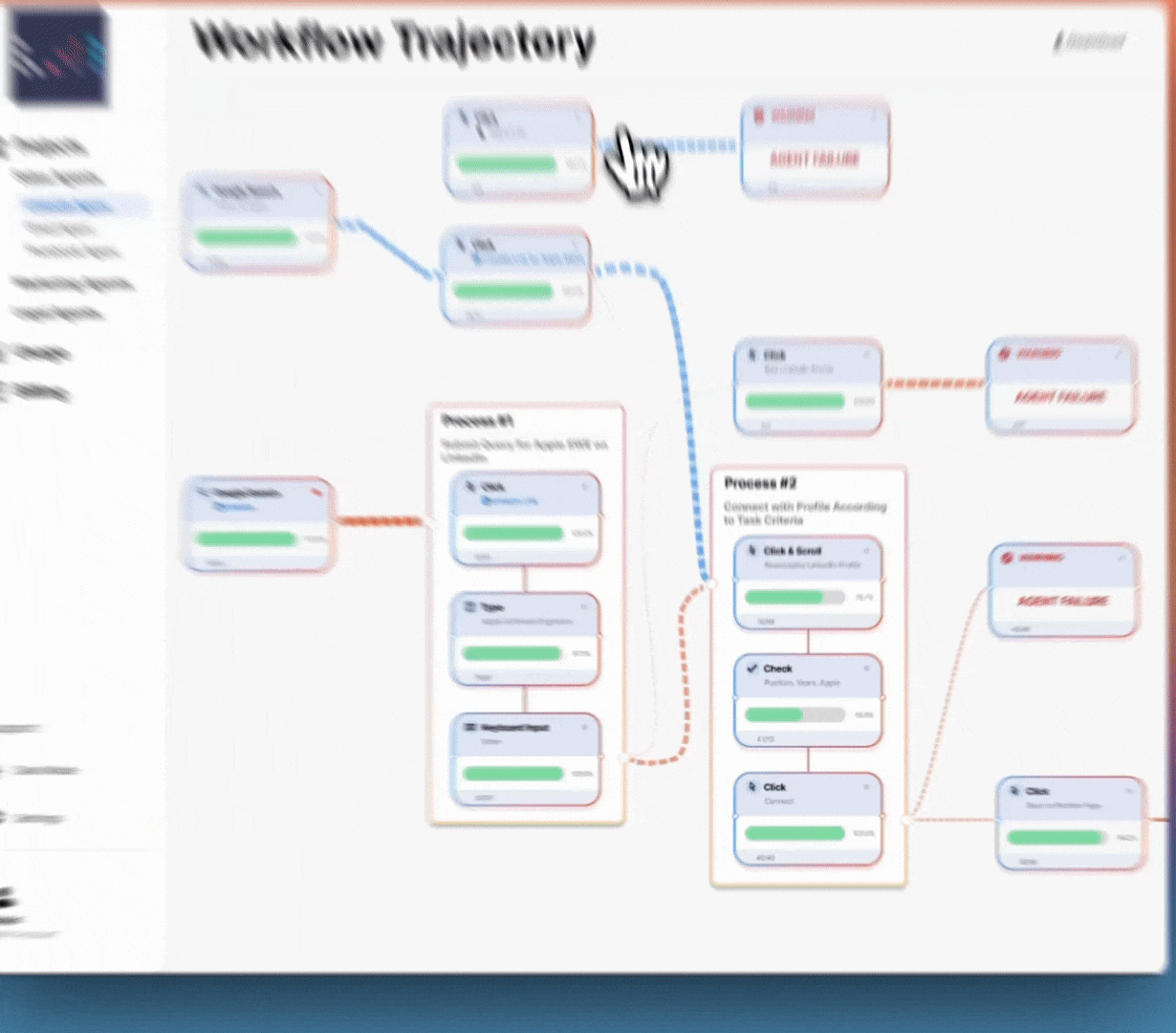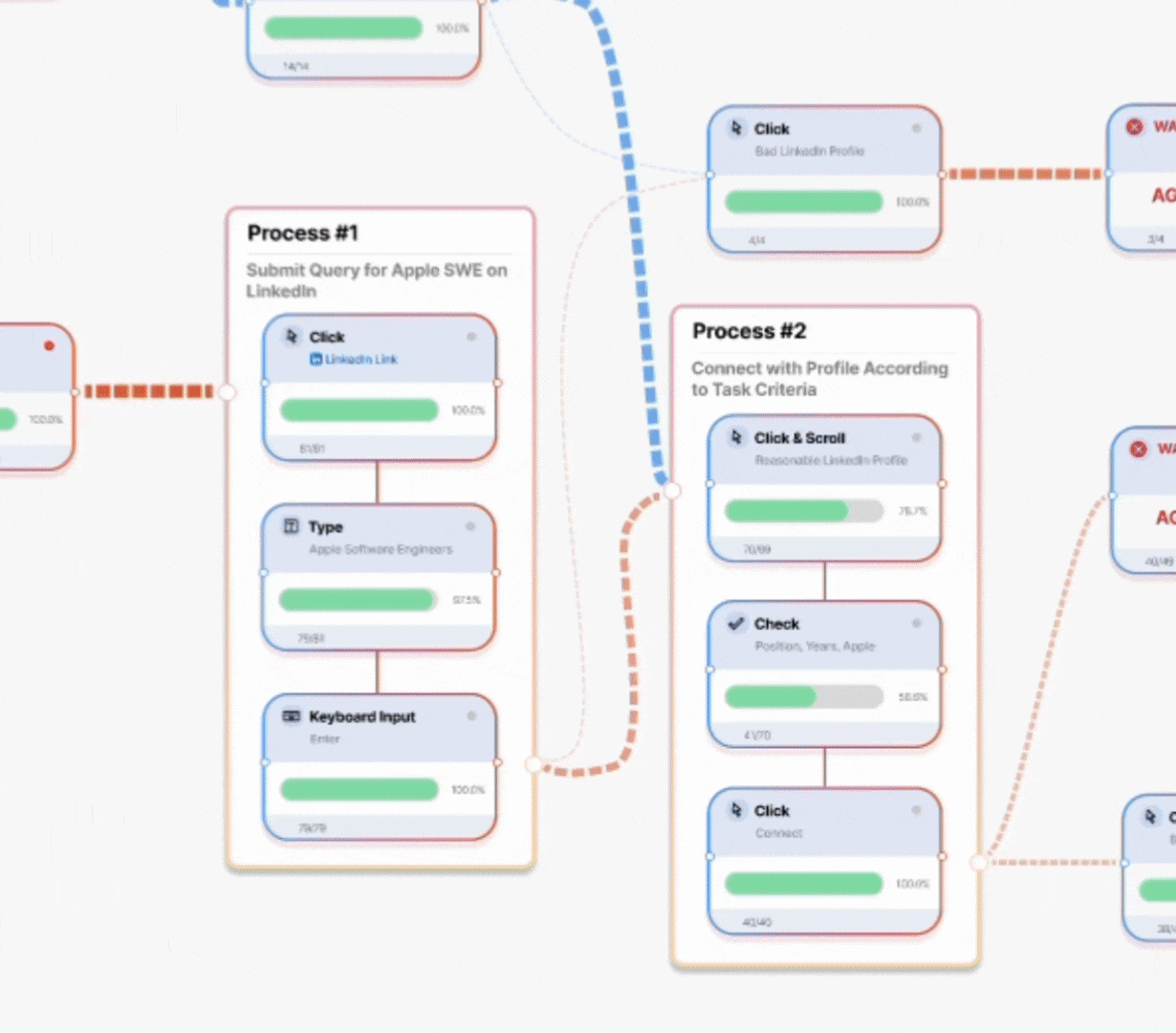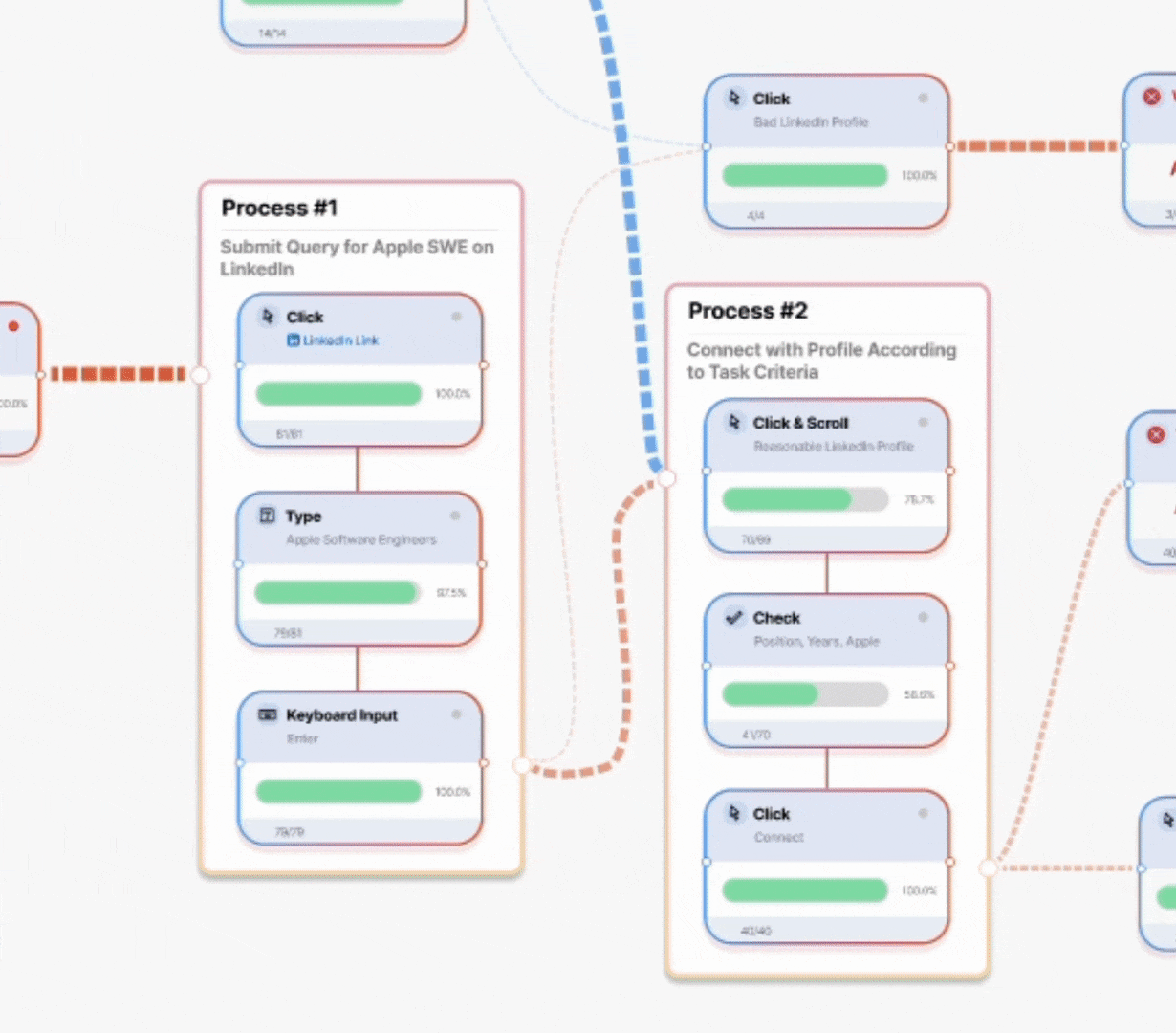
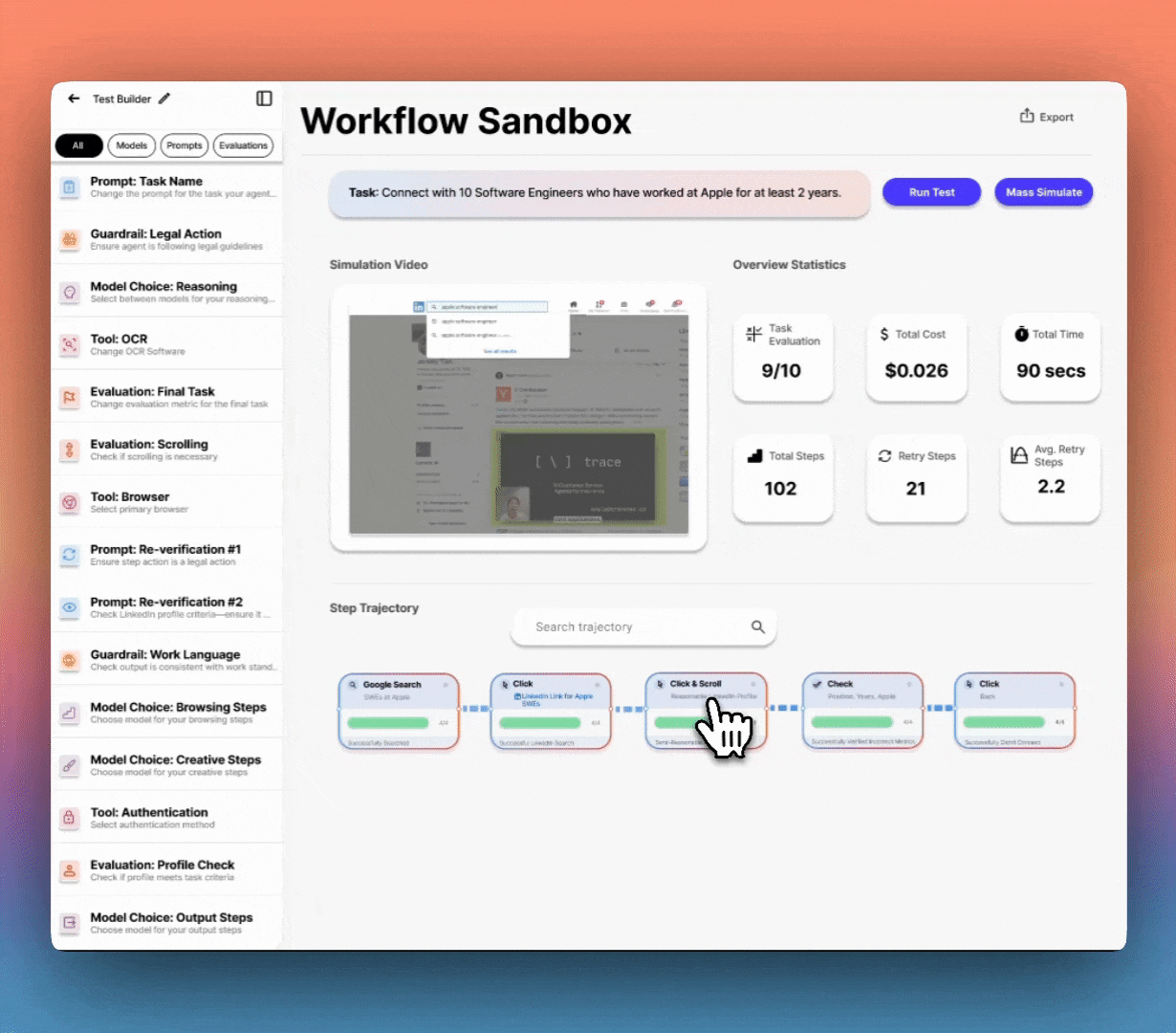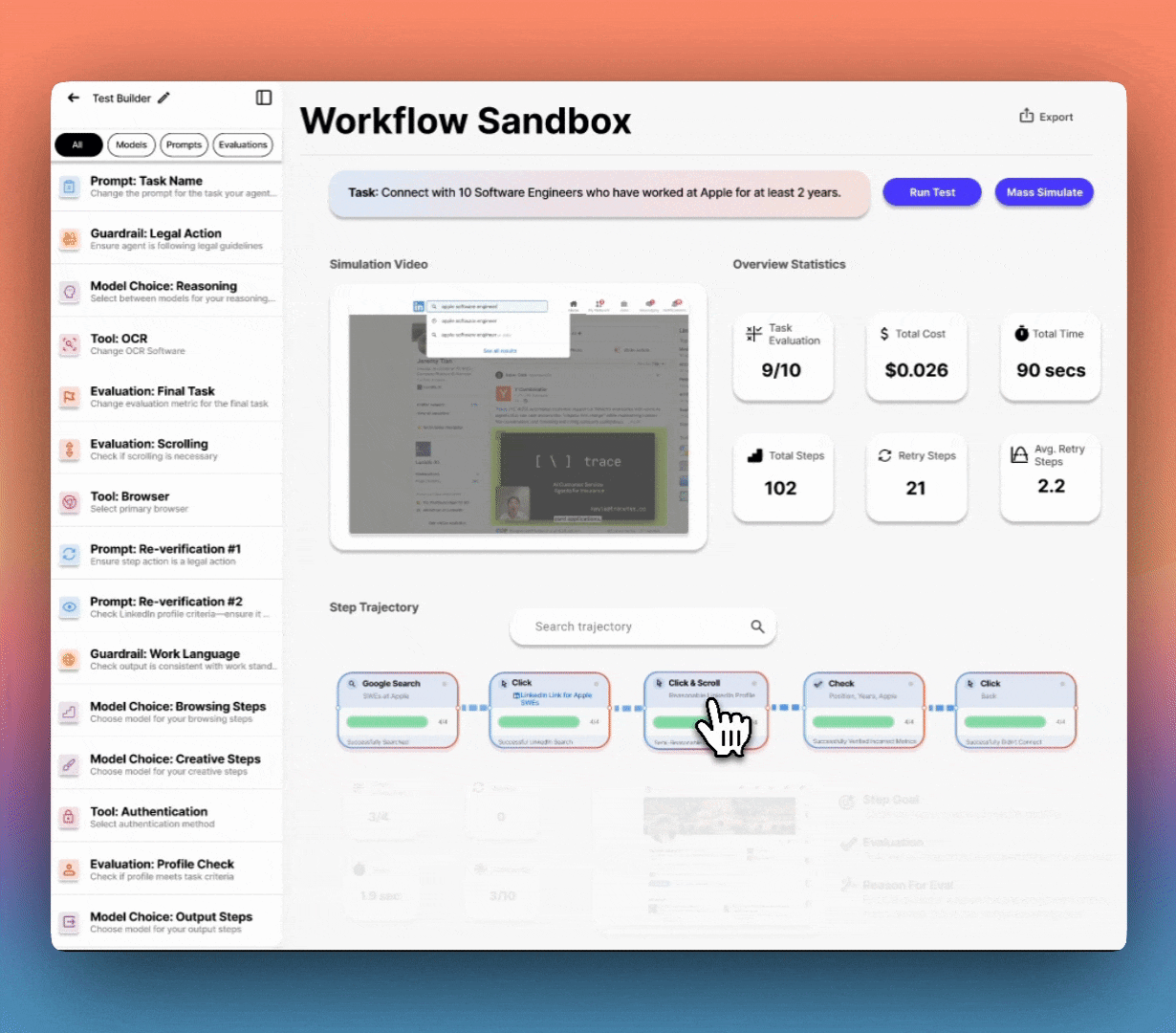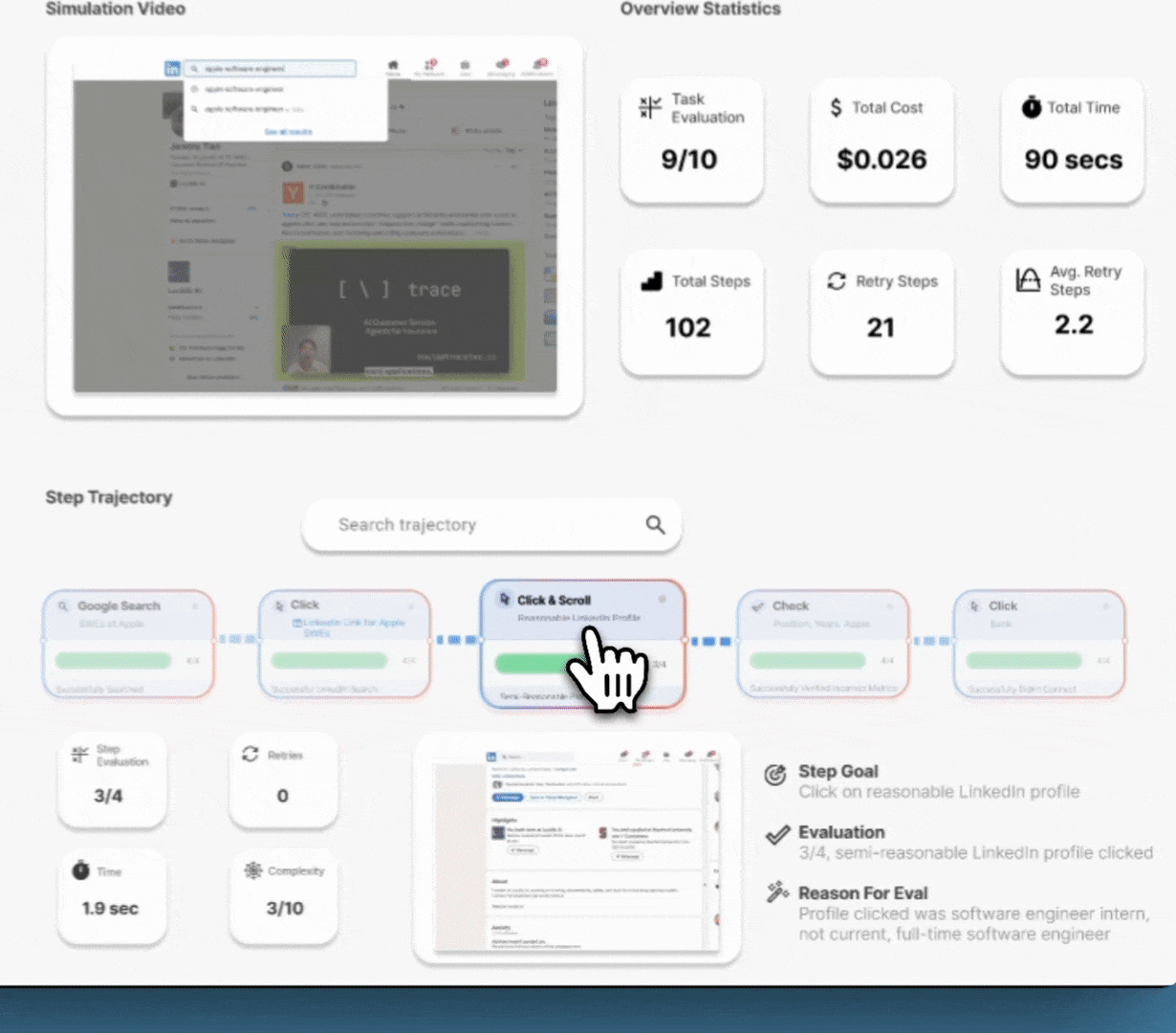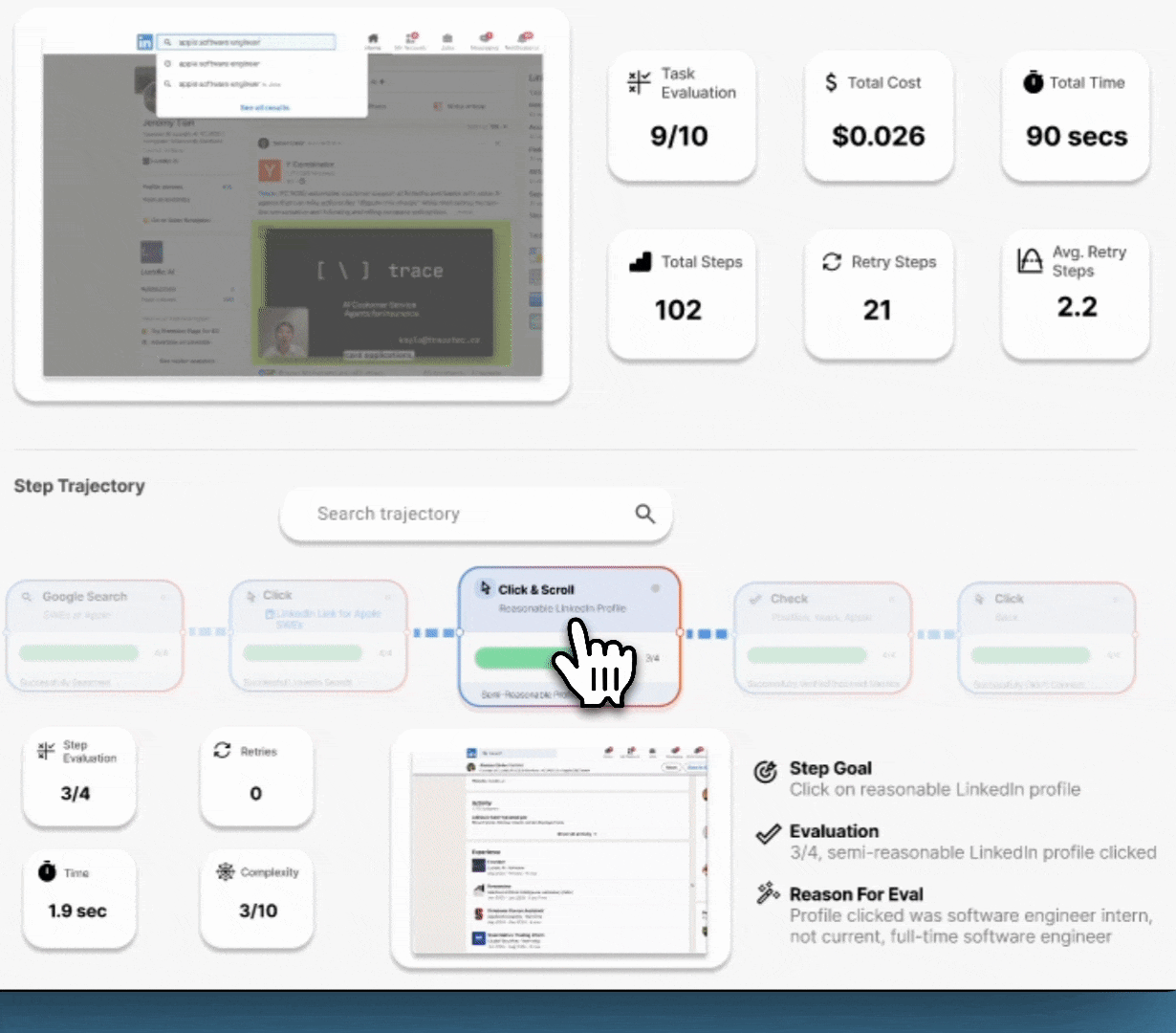
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Built for Delaware C-Corps. Trusted by 1,000+ startups.
Copyright © Fondo (BloomJoy, Inc.)




