.png)


Founded by Bobby Zhong & Kurt Sharma
As good as general, closed source models are, they just aren’t built for your use case.
Burt helps teams train and deploy custom models built specifically for their domain and use case.
They help with every step of the process, from data prep and evals to training and deployment.
Using the latest post-training and inference stack they have built in house, they deliver models that outperform SOTA while being a fraction of the cost and latency.
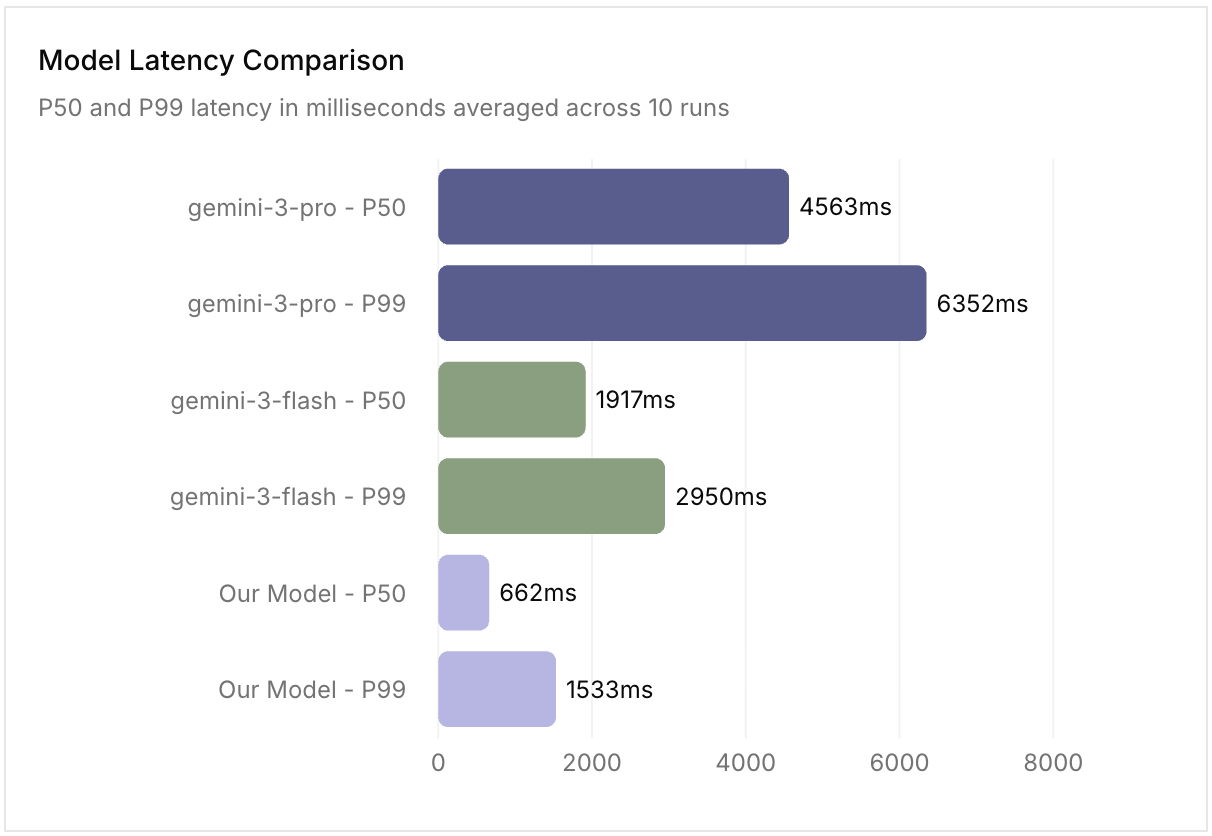
For one of their customers (more details coming soon!), they had a model call that saw extremely high volume and had issues with it being too slow even with gemini-3-flash.
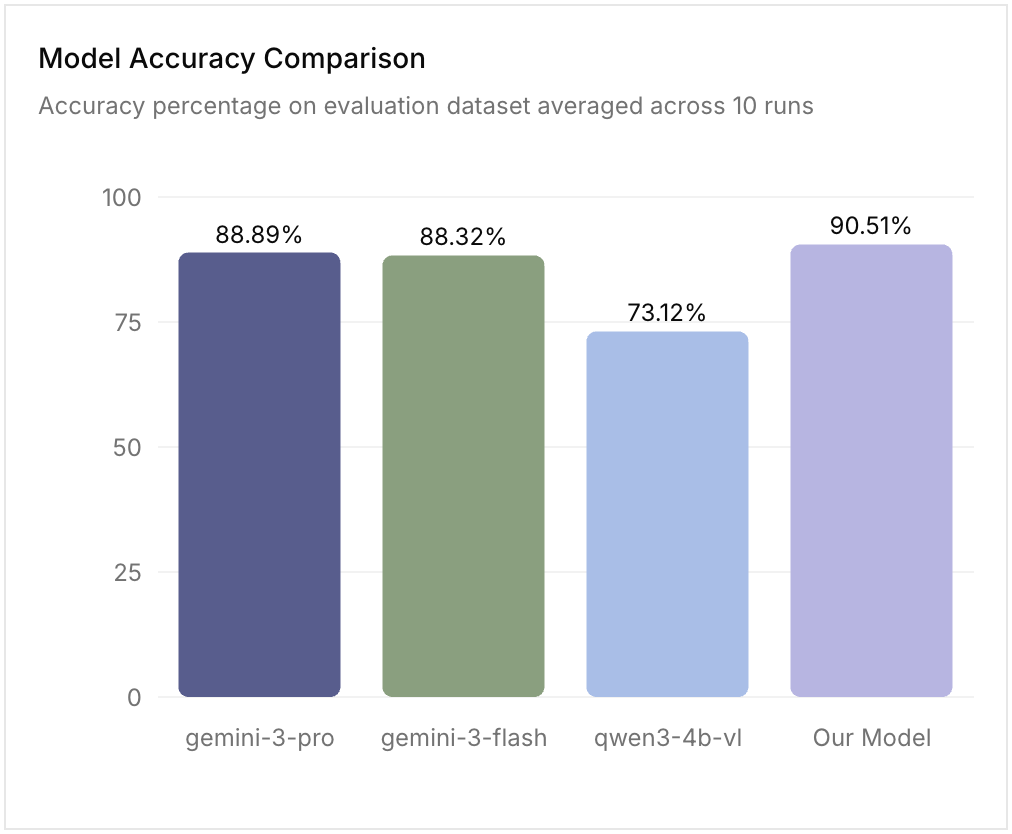
To solve that, they built a small vision language model (VLM) that’s ~3x faster (p50) while being MORE accurate than gemini-3-flash/pro.
Now they are continuing to improve that model and closing that last 10%
If you’re building AI agents and either of the following apply, the team would love to help:
Book a chat here or email them here.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Built for Delaware C-Corps. Trusted by 1,000+ startups.
Copyright © Fondo (BloomJoy, Inc.)




